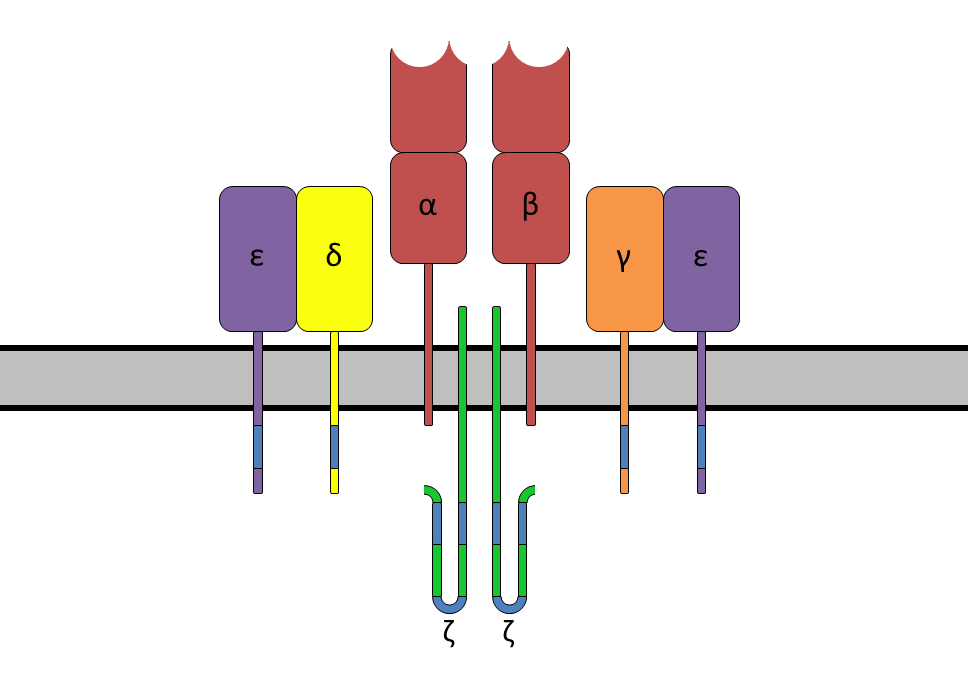
The T-cell receptor (TCR) is a protein complex found on the surface of T cells, or T lymphocytes, that is responsible for recognizing fragments of antigen as peptides bound to major histocompatibility complex (MHC) molecules. The binding between TCR and antigen peptides is of relatively low affinity and is degenerate: that is, many TCRs recognize the same antigen peptide and many antigen peptides are recognized by the same TCR.
The TCR is composed of two different protein chains (that is, it is a heterodimer). In humans, in 95% of T cells the TCR consists of an alpha (α) chain and a beta (β) chain (encoded by TRA and TRB, respectively), whereas in 5% of T cells the TCR consists of gamma and delta (γ/δ) chains (encoded by TRG and TRD, respectively). This ratio changes during ontogeny and in diseased states (such as leukemia). It also differs between species. Orthologues of the 4 loci have been mapped in various species. Each locus can produce a variety of polypeptides with constant and variable regions.
When the TCR engages with antigenic peptide and MHC (peptide/MHC), the T lymphocyte is activated through signal transduction, that is, a series of biochemical events mediated by associated enzymes, co-receptors, specialized adaptor molecules, and activated or released transcription factors. Based on the initial receptor triggering mechanism, the TCR belongs to the family of Non-catalytic tyrosine-phosphorylated receptors (NTRs). (W)
A diagram showing the alpha-beta T cell receptor complex, including associated CD3 proteins. The blue segments are the ITAMs.
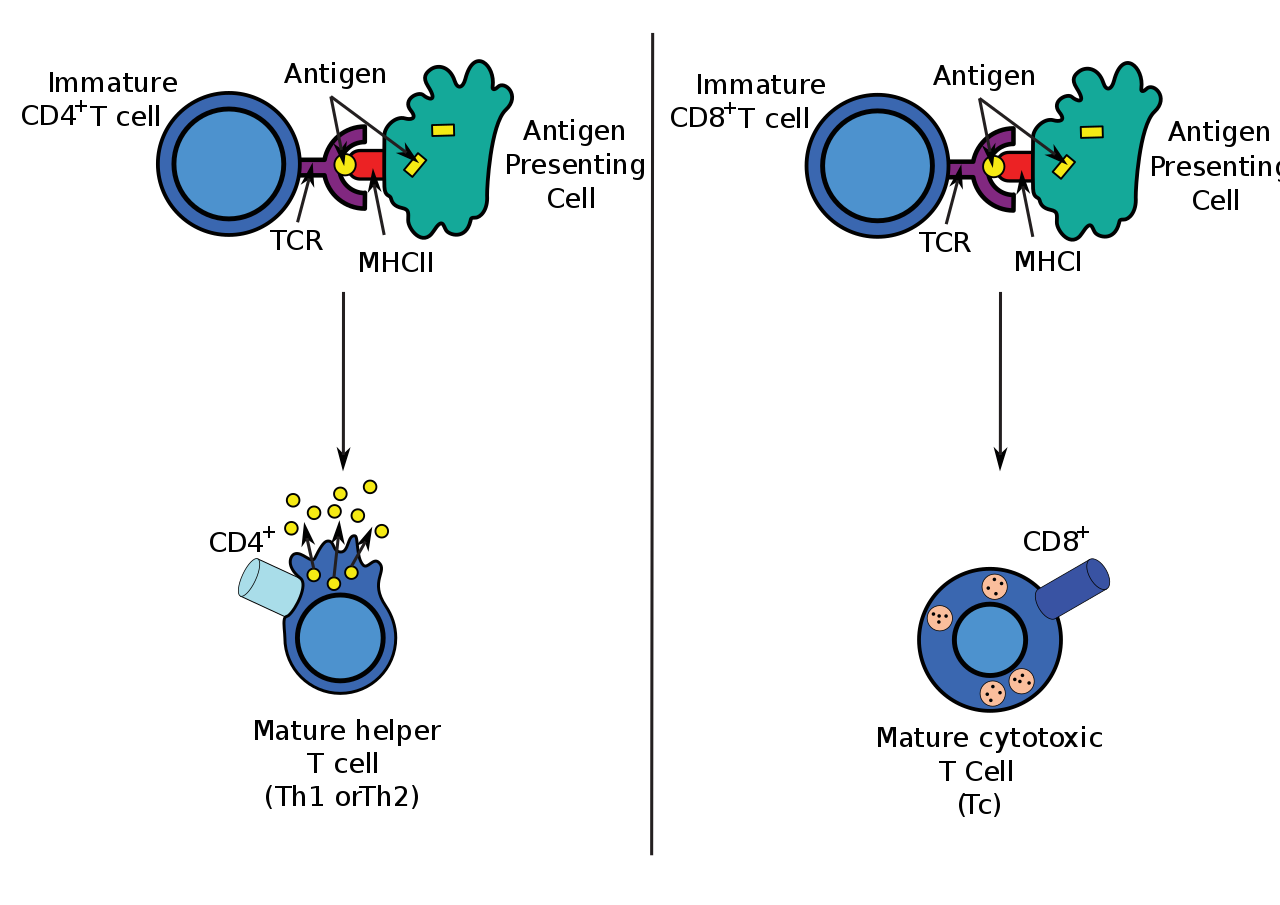
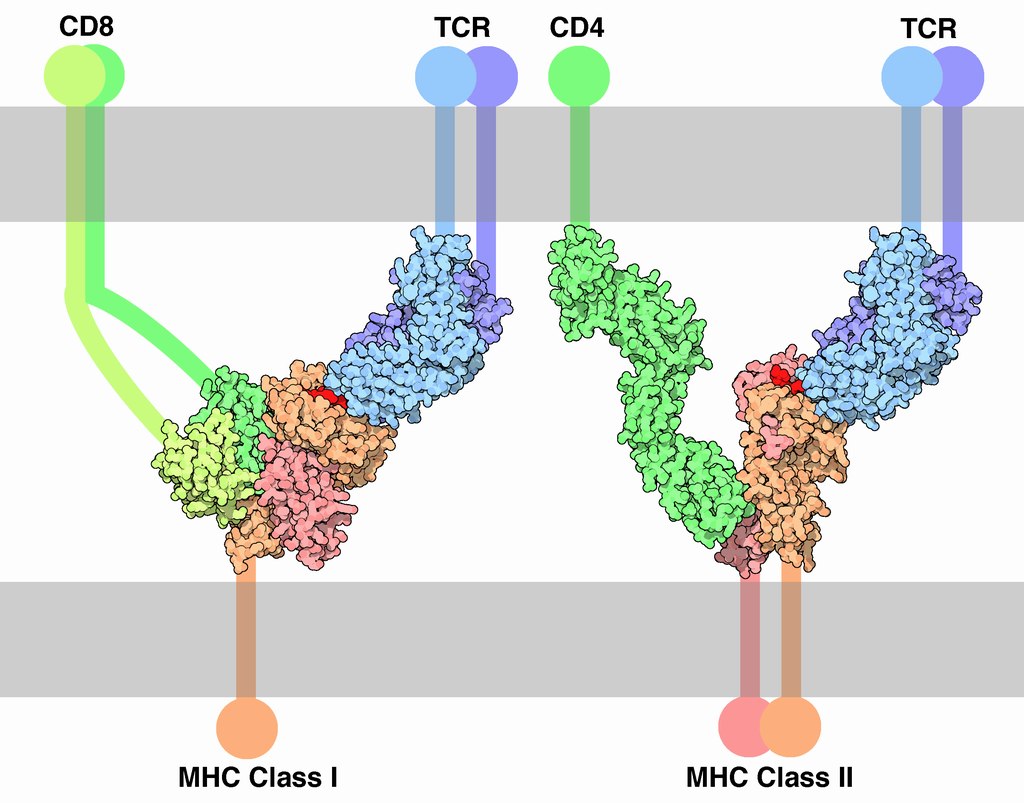
Antigen presentation stimulates T cells to become either "cytotoxic" CD8+ cells or "helper" CD4+ cells.
Antigen presentation stimulates T cells to activate "cytotoxic" CD8+ cells or "helper" CD4+ cells. Cytotoxic cells directly attack other cells carrying certain foreign or abnormal molecules on their surfaces. Helper T cells, or Th cells, coordinate immune responses by communicating with other cells. In most cases, T cells only recognize an antigen if it is carried on the surface of a cell by one of the body’s own MHC, or major histocompatibility complex, molecules.
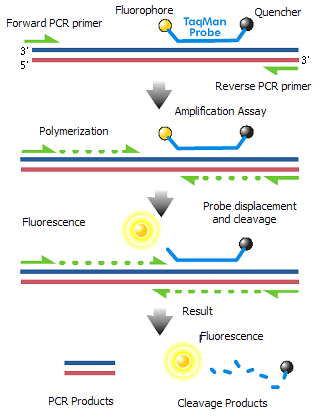
The TaqMan probe principle relies on the 5´–3´ exonuclease activity of Taq polymerase to cleave a dual-labeled probe during hybridization to the complementary target sequence and fluorophore-based detection. As in other quantitative PCR methods, the resulting fluorescence signal permits quantitative measurements of the accumulation of the product during the exponential stages of the PCR; however, the TaqMan probe significantly increases the specificity of the detection. TaqMan probes were named after the videogame Pac-Man (Taq Polymerase + PacMan = TaqMan) as its mechanism is based on the Pac-Man principle. (W)
TaqMan probe chemistry mechanism.
telomere
A telomere is a region of repetitive nucleotide sequences at each end of a chromosome,which protects the end of the chromosome from deterioration or from fusion with neighboring chromosomes. Its name is derived from the Greek nouns telos (τέλος) "end" and merοs (μέρος, root: μερ-) "part". For vertebrates, the sequence of nucleotides in telomeres is 5′-TTAGGG-3′, with the complementary DNA strand being 3′-AATCCC-5′, with a single-stranded TTAGGG overhang. This sequence of TTAGGG is repeated approximately 2,500 times in humans. In humans, average telomere length declines from about 11 kilobases at birth to fewer than 4 kilobases in old age, with the average rate of decline being greater in men than in women.
During chromosome replication, the enzymes that duplicate DNA cannot continue their duplication all the way to the end of a chromosome, so in each duplication the end of the chromosome is shortened (this is because the synthesis of Okazaki fragments requires RNA primers attaching ahead on the lagging strand). The telomeres are disposable buffers at the ends of chromosomes which are truncated during cell division; their presence protects the genes before them on the chromosome from being truncated instead. The telomeres themselves are protected by a complex of shelterin proteins, as well as by the RNA that telomeric DNA encodes (TERRA).
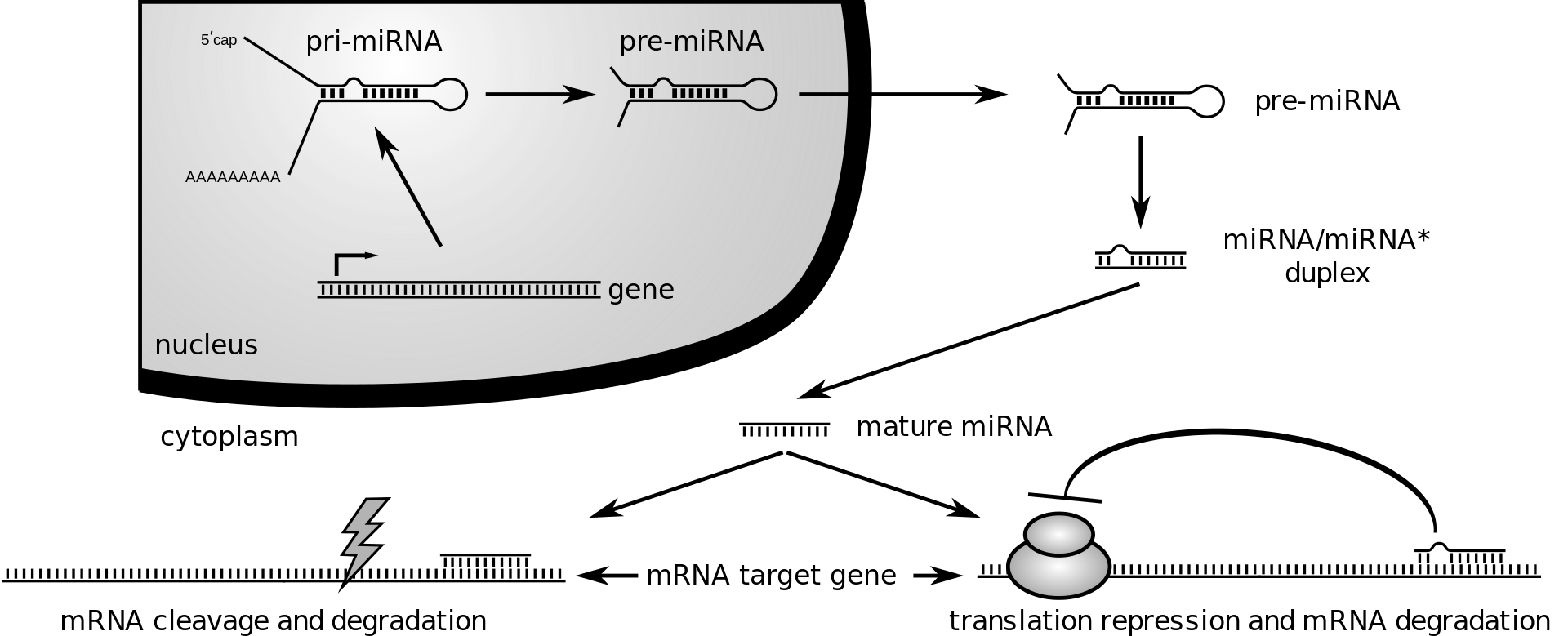
During gene expression, an mRNA molecule is transcribed from the DNA sequence and is later translated into a protein. Several regions of the mRNA molecule are not translated into a protein including the 5' cap,5' untranslated region, 3′ untranslated region and poly(A) tail. Regulatory regions within the 3′-untranslated region can influence polyadenylation, translation efficiency, localization, and stability of the mRNA. The 3′-UTR contains both binding sites for regulatory proteins as well as microRNAs (miRNAs). By binding to specific sites within the 3′-UTR, miRNAs can decrease gene expression of various mRNAs by either inhibiting translation or directly causing degradation of the transcript. The 3′-UTR also has silencer regions which bind to repressor proteins and will inhibit the expression of the mRNA.
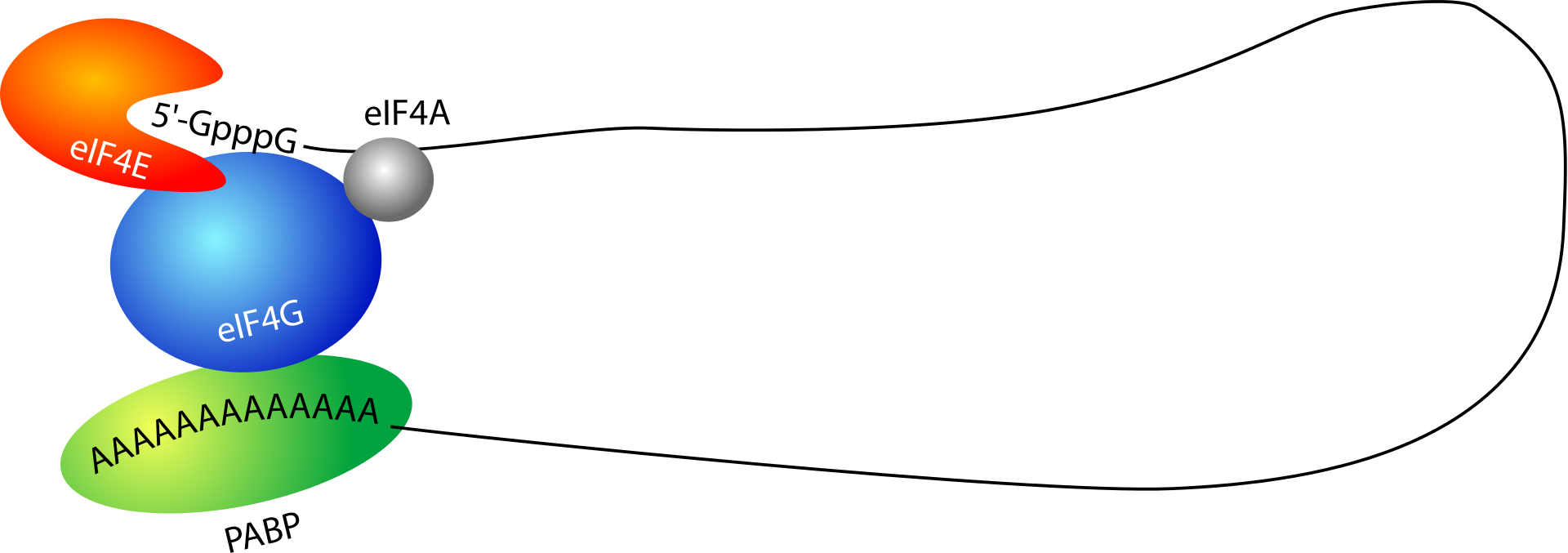
Many 3′-UTRs also contain AU-rich elements (AREs). Proteins bind AREs to affect the stability or decay rate of transcripts in a localized manner or affect translation initiation. Furthermore, the 3′-UTR contains the sequence AAUAAA that directs addition of several hundred adenine residues called the poly(A) tail to the end of the mRNA transcript. Poly(A) binding protein (PABP) binds to this tail, contributing to regulation of mRNA translation, stability, and export. For example, poly (A) tail bound PABP interacts with proteins associated with the 5' end of the transcript, causing a circularization of the mRNA that promotes translation.
The 3′-UTR can also contain sequences that attract proteins to associate the mRNA with the cytoskeleton, transport it to or from the cell nucleus, or perform other types of localization. In addition to sequences within the 3′-UTR, the physical characteristics of the region, including its length and secondary structure, contribute to translation regulation. These diverse mechanisms of gene regulation ensure that the correct genes are expressed in the correct cells at the appropriate times. (W)
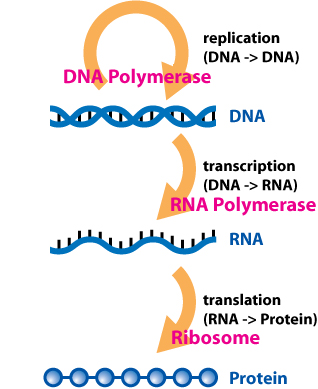
The flow of information within a cell. DNA is first transcribed into RNA, which is subsequently translated into protein. (See Central dogma of molecular biology).
mRNA structure, approximately to scale for a human mRNA, where the median length of 3′UTR is 700 nucleotides.
Diagramatic structure of a typical human protein coding mRNA including the untranslated regions (UTRs).It is drawn approximately to scale. The cap is only one modified base, average en:5' UTR length 170, en:3' UTR 700. Reproduced from http://commons.wikimedia.org/wiki/Image:MRNA_structure.png .
Circularization of the mRNA transcript is mediated by proteins interacting with the 5' cap and poly(A) tail.
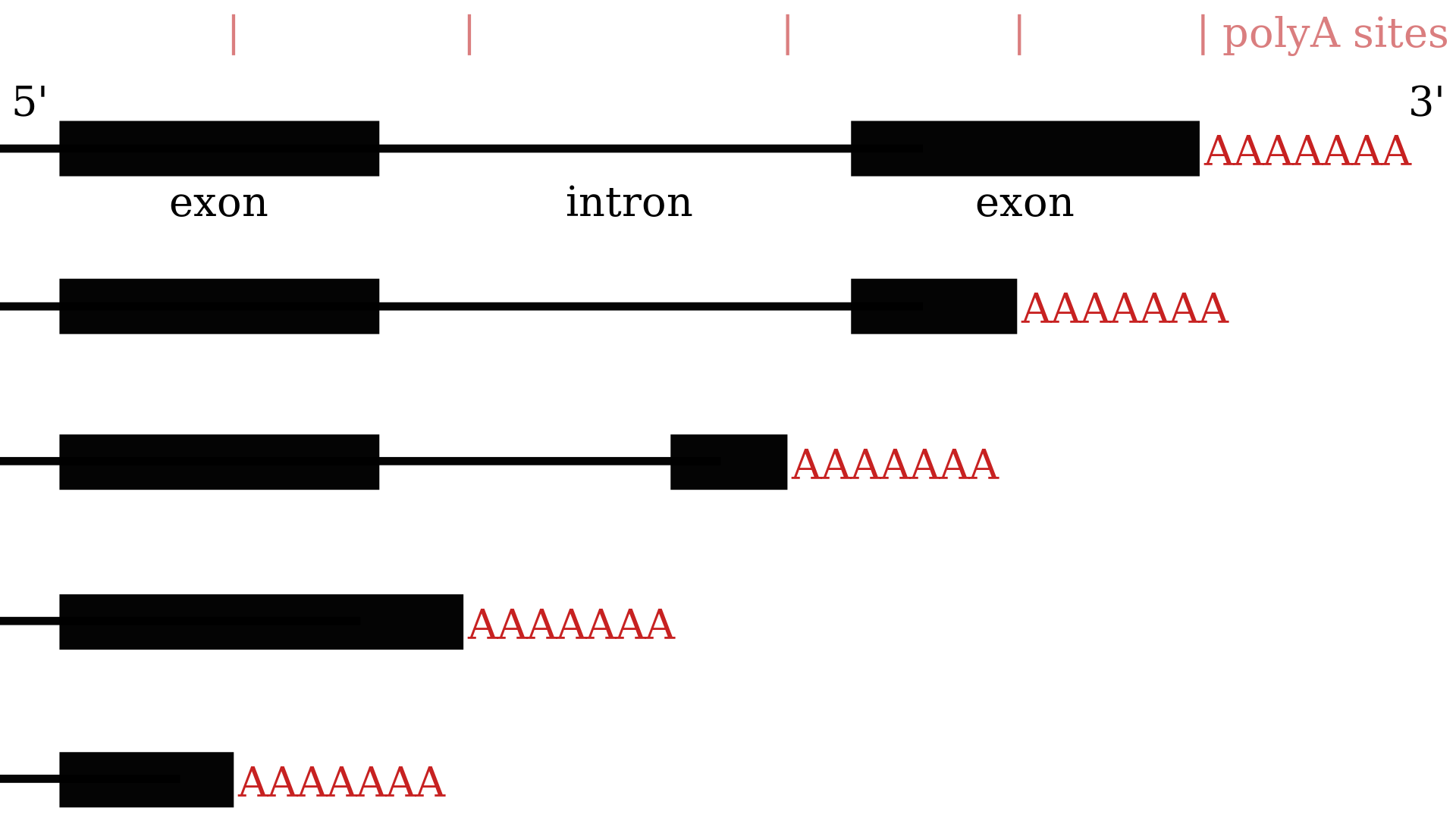
Alternative polyadenylation results in transcripts with different 3′-UTRs.
Illustration of how alternative polyadenylation can result in many variants of the 3'-most part of an mRNA. Compared to the first mRNA, the second one shows tandem polyadenylation sites, the third a hidden exon, the fourth composite exons and the fifth a truncated exon.
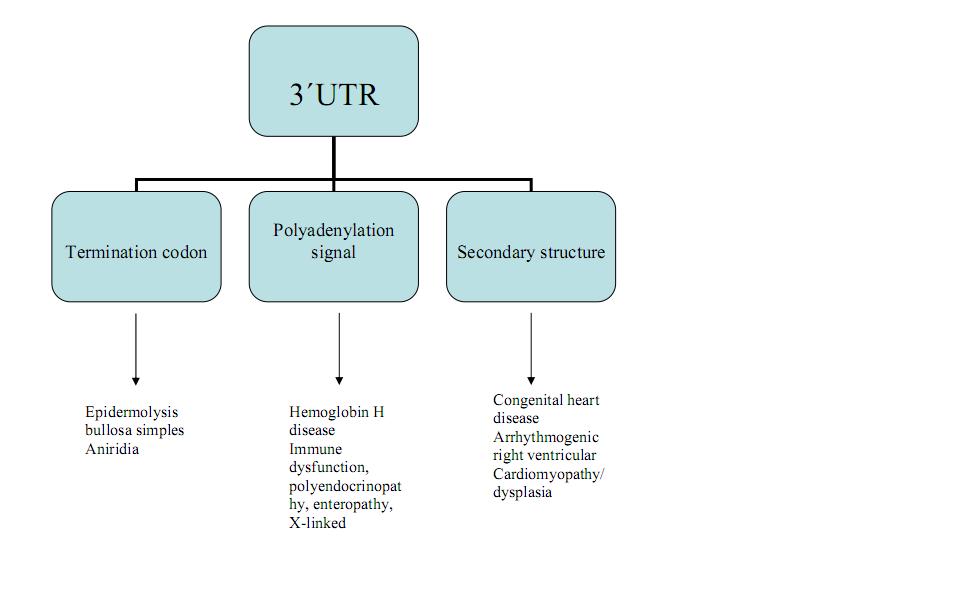
Diseases caused by different mutations within the 3′-UTR.
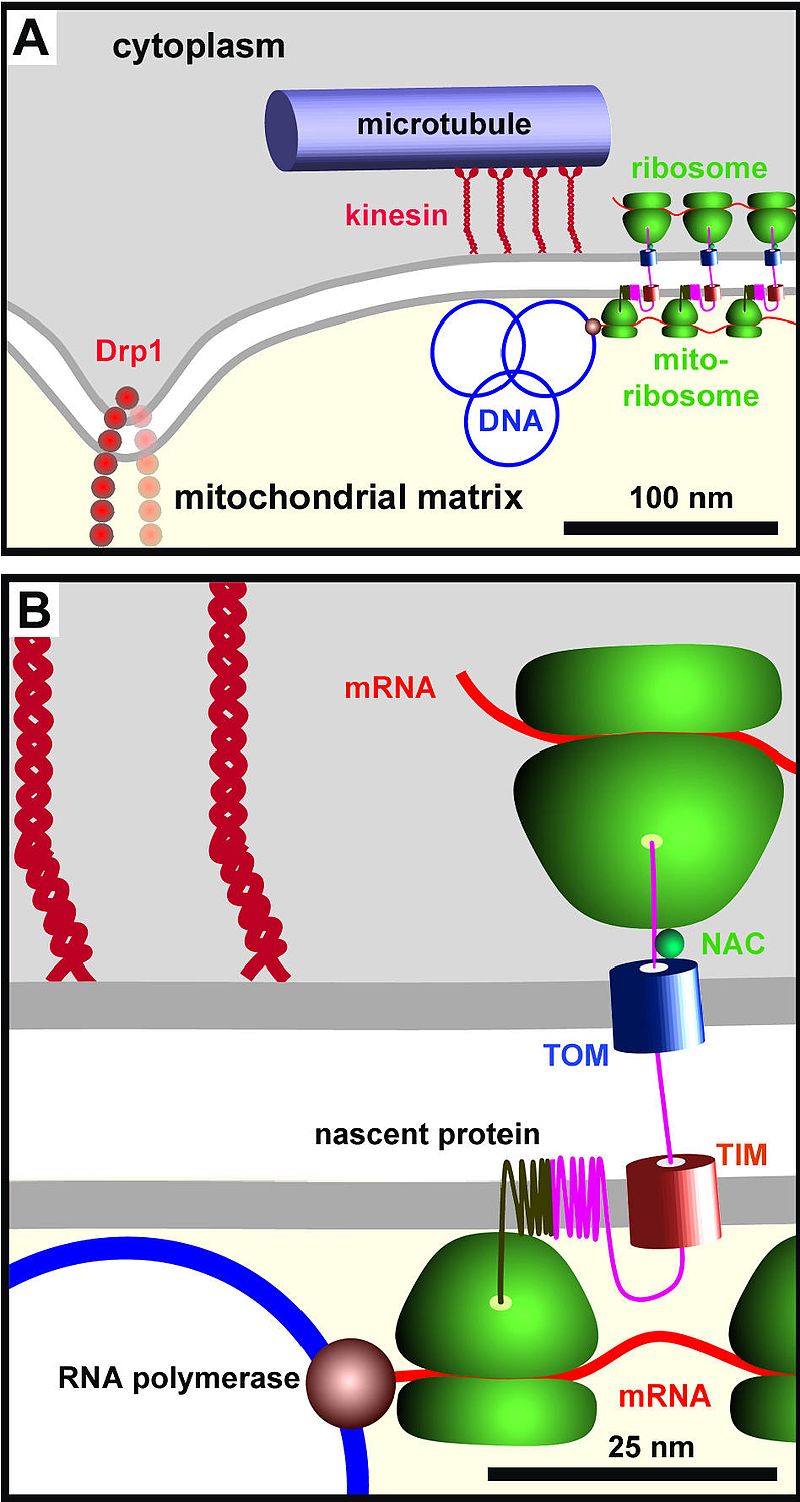
The vast majority of proteins destined for the mitochondria are encoded in the nucleus and synthesized in the cytoplasm. These are tagged by an N-terminal signal sequence. Following transport through the cytosol from the nucleus, the signal sequence is recognized by a receptor protein in the translocase of the outer membrane (TOM) complex. The signal sequence and adjacent portions of the polypeptide chain are inserted in the TOM complex, then begin interaction with a translocase of the inner membrane (TIM) complex, which are hypothesized to be transiently linked at sites of close contact between the two membranes. The signal sequence is then translocated into the matrix in a process that requires an electrochemical hydrogen ion gradient across the inner membrane. Mitochondrial Hsp70 binds to regions of the polypeptide chain and maintains it in an unfolded state as it moves into the matrix. (W)
Simplified representation of the Mitochondrial DNA Organization proteins (top image). A close up of a single ribosome in coordination with the TOM complex on the outer Mitochondrial membrane and the TIM complex on the inner Mitochondrial membrane (bottom image). The nascent transmembrane protein is being fed into the mitochondrial membrane where its target peptide (not shown) gets cleaved.
A cartoon illustrating the components studied here (drawn roughly to scale) that lie within the sphere of influence of mtDNA. (A) A cluster of approximately eight mitochondrial genomes (see Table 1; only three are shown) are tethered through the mitochondrial membranes (see Figure 2) to kinesin and cytoplasmic microtubular network (see Figure 3); tethering restricts motion (see Figure 4), but the molecular mechanism is unknown. A cluster is usually found in a thin part of the mitochondrion poor in YFP-cytochrome oxidase (Figure 1G), and mitochondria generally split near Drp1 foci lying ~300 nm away (Figure 5). (B) A high-power view of a region in (A). Nascent mtRNA is translated cotranscriptionally by mitochondrial ribosomes bound both to the polymerase [40] and the inner mitochondrial membrane ; completed mRNAs (not shown) are also translated during most of their lifetime in this region (Figure 7J). The cytoplasmic translation machinery that makes nuclear-encoded proteins destined for the mitochondrion – marked by a ribosomal protein (S6) and a chaperone (NAC) – lie immediately on the other side of the mitochondrial membrane (Figure 8A,8B,8C,8D,8E,8F,8G,8H). Here, a cytoplasmic peptide is being made and imported through the translocases in the outer and inner membranes (TOM and TIM; TOM is marked by Tom22; Figure 8I,8J,8K,8L) where it will assemble with a mitochondrial-encoded peptide in the inner mitochondrial membrane. The close proximity of the two sets of machinery on each side of the membranes ensures efficient assembly of mitochondrial complexes containing proteins encoded by nuclear and mitochondrial genomes. Iborra et al. BMC Biology 2004 2:9 doi:10.1186/1741-7007-2-9 .
toxin-antitoxin system
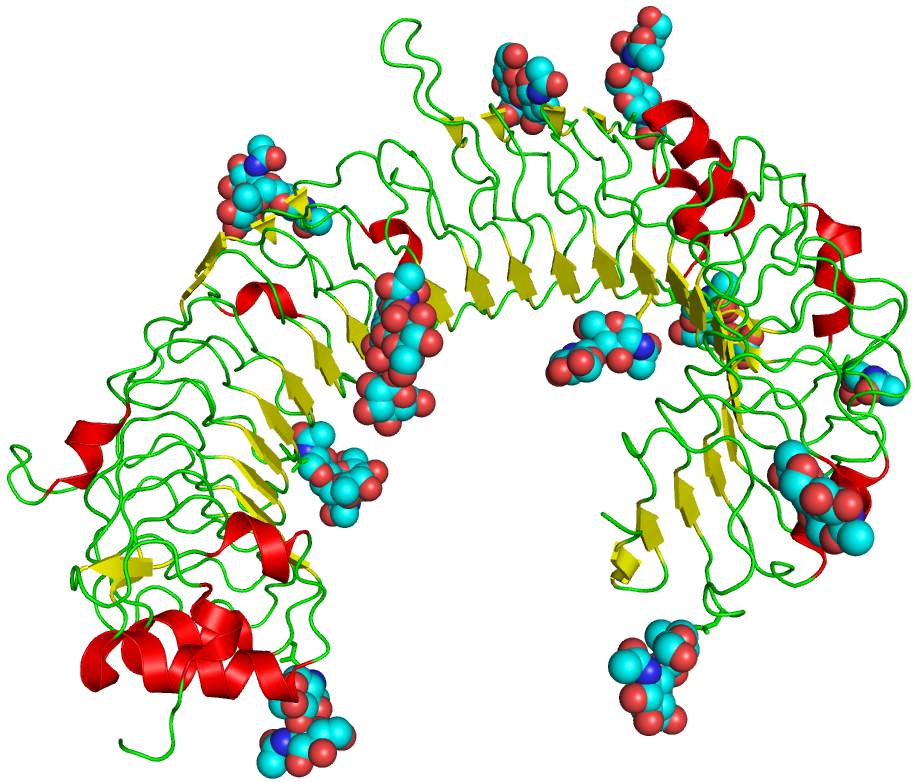
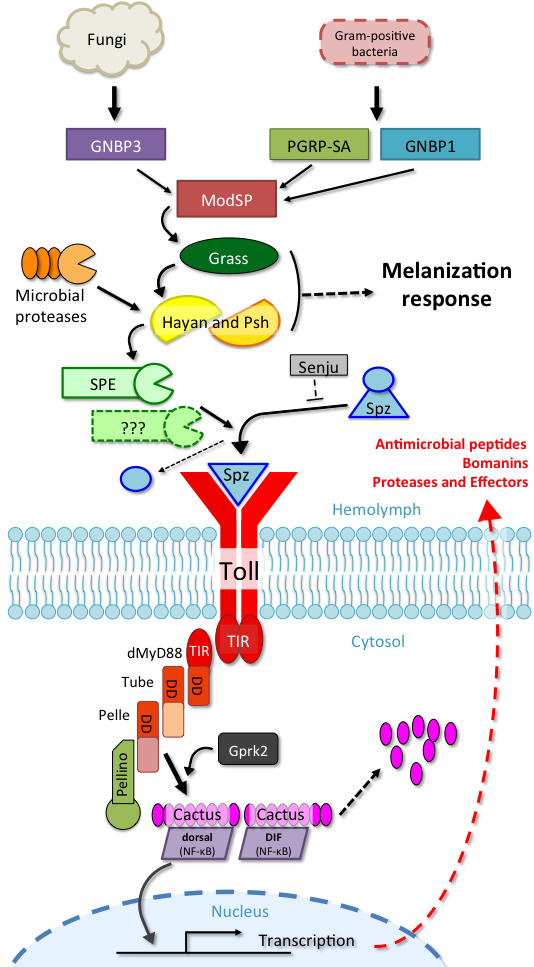
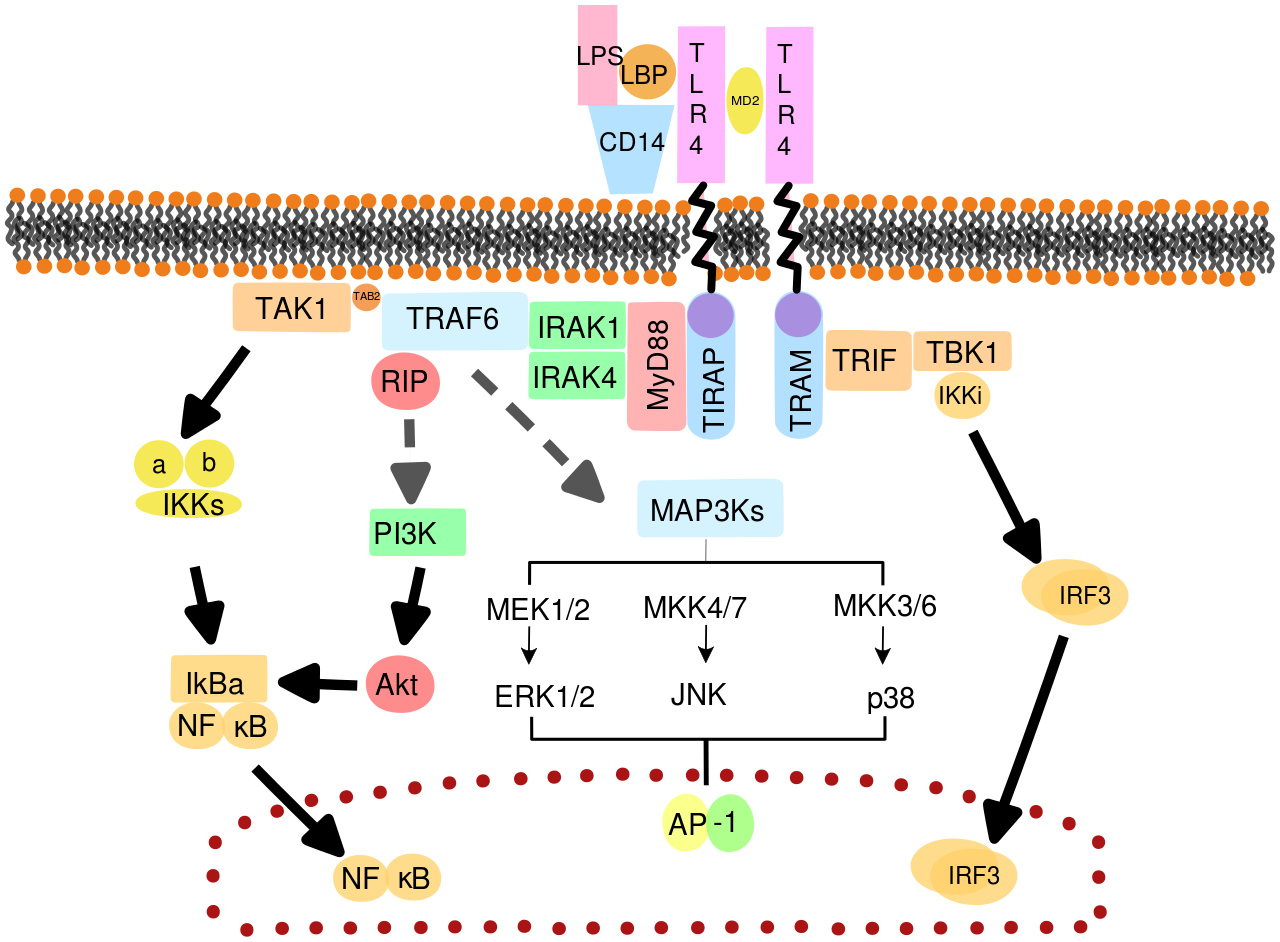
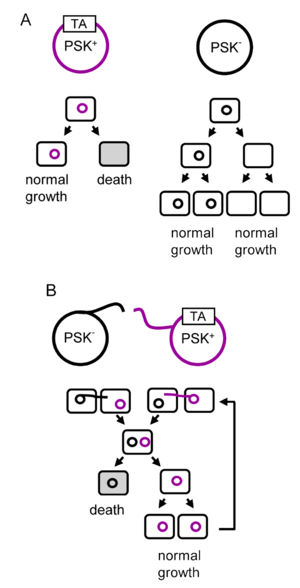
A toxin-antitoxin system is a set of two or more closely linked genes that together encode both a "toxin" protein and a corresponding "antitoxin". Toxin-antitoxin systems are widely distributed in prokaryotes, and organisms often have them in multiple copies. When these systems are contained on plasmids – transferable genetic elements – they ensure that only the daughter cells that inherit the plasmid survive after cell division. If the plasmid is absent in a daughter cell, the unstable antitoxin is degraded and the stable toxic protein kills the new cell; this is known as 'post-segregational killing' (PSK).(W)
(A) The vertical gene transfer of a toxin-antitoxin system. (B) Horizontal gene transfer of a toxin-antitoxin system. PSK stands for post-segregational killing and TA represents a locus encoding a toxin and an antitoxin.
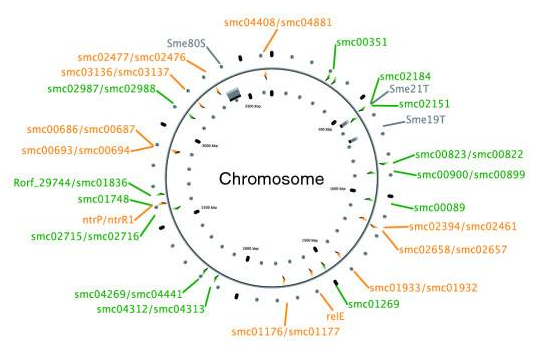
A chromosome map of Sinorhizobium meliloti, with its 25 chromosomal toxin-antitoxin systems. Orange-labelled loci are confirmed TA systems and green labels show putative systems.
RNA polymerase generates a transcription bubble, which separates the two strands of the DNA helix. This is done by breaking the hydrogen bonds between complementary DNA nucleotides.
RNA polymerase adds RNA nucleotides (which are complementary to the nucleotides of one DNA strand).
RNA sugar-phosphate backbone forms with assistance from RNA polymerase to form an RNA strand.
Hydrogen bonds of the RNA–DNA helix break, freeing the newly synthesized RNA strand.
The RNA may remain in the nucleus or exit to the cytoplasm through the nuclear pore complex.
The stretch of DNA transcribed into an RNA molecule is called a transcription unit and encodes at least one gene. If the gene encodes a protein, the transcription produces messenger RNA (mRNA); the mRNA, in turn, serves as a template for the protein's synthesis through translation. Alternatively, the transcribed gene may encode for non-coding RNA such as microRNA,ribosomal RNA (rRNA), transfer RNA (tRNA), or enzymatic RNA molecules called ribozymes. Overall, RNA helps synthesize, regulate, and process proteins; it therefore plays a fundamental role in performing functions within a cell.
In virology, the term may also be used when referring to mRNA synthesis from an RNA molecule (i.e., RNA replication). For instance, the genome of a negative-sense single-stranded RNA (ssRNA -) virus may be template for a positive-sense single-stranded RNA (ssRNA +). This is because the positive-sense strand contains the information needed to translate the viral proteins for viral replication afterwards. This process is catalyzed by a viral RNA replicase.
Transcription is the process of copying genetic code from DNA into RNA. Initially, an activator protein attaches to the DNA strand. A TATA Binding Protein, or TBP, paired with transcription factor II D, then binds to a specific site on the DNA. Transcription factor proteins TFIIA, TFIIB, and TFIIH attach to the gene and surround the TBP. Next, RNA polymerase binds to DNA in front of the transcription factors, followed by TFIIE and TFIIF. After a mediator protein attaches, a DNA bending protein causes the DNA to change shape, which starts transcription. Transcription begins when the mediator protein makes contact with the activator protein. More proteins then bind to the polymerase forming a CTD (carboxyl-terminal domain) tail, which activates the polymerase. TFIIA, TFIIB, TFIID, TFIIH, TBP, and the mediator protein break from the DNA, propelling the polymerase. As the polymerase spirals down and unzips the DNA, free nucleotides pair with complementary DNA bases. In DNA, cytosine pairs with guanine and adenine pairs with thymine. During transcription, cytosine still pairs to guanine, but uracil replaces thymine to pair with adenine. As nucleotides attach to their complement bases, a sugar-phosphate backbone forms. Transcribed messenger RNA, or mRNA, grows until the polymerase reaches the end of the gene, releases the completed mRNA strand, and detaches from the DNA.
transcription factor
In molecular biology, a transcription factor (TF) (or sequence-specific DNA-binding factor) is a protein that controls the rate of transcription of genetic information from DNA to messenger RNA, by binding to a specific DNA sequence. The function of TFs is to regulate—turn on and off—genes in order to make sure that they are expressed in the right cell at the right time and in the right amount throughout the life of the cell and the organism. Groups of TFs function in a coordinated fashion to direct cell division,cell growth, and cell death throughout life; cell migration and organization (body plan) during embryonic development; and intermittently in response to signals from outside the cell, such as a hormone. There are up to 1600 TFs in the human genome.
TFs work alone or with other proteins in a complex, by promoting (as an activator), or blocking (as a repressor) the recruitment of RNA polymerase (the enzyme that performs the transcription of genetic information from DNA to RNA) to specific genes.
transcription factor – a protein that binds to DNA and regulates gene expression by promoting or suppressing transcription
transcriptional regulation – controlling the rate of gene transcription for example by helping or hindering RNA polymerase binding to DNA
upregulation, activation, or promotion – increase the rate of gene transcription
downregulation, repression, or suppression – decrease the rate of gene transcription
coactivator – a protein that works with transcription factors to increase the rate of gene transcription
corepressor – a protein that works with transcription factors to decrease the rate of gene transcription
response element – a specific sequence of DNA that a transcription factor binds to
transcriptome
The transcriptome is the set of all RNA transcripts, including coding and non-coding, in an individual or a population of cells. The term can also sometimes be used to refer to all RNAs, or just mRNA, depending on the particular experiment. The term transcriptome is a portmanteau of the words transcript and genome; it is associated with the process of transcript production during the biological process of transcription.(W)
Transduction is the process by which foreign DNA is introduced into a cell by a virus or viral vector. An example is the viral transfer of DNA from one bacterium to another and hence an example of horizontal gene transfer. Transduction does not require physical contact between the cell donating the DNA and the cell receiving the DNA (which occurs in conjugation), and it is DNase resistant (transformation is susceptible to DNase). Transduction is a common tool used by molecular biologists to stably introduce a foreign gene into a host cell's genome (both bacterial and mammalian cells). (W)
Transduction.
An illustration of the difference between generalized transduction, which is the process of transferring any bacterial gene to a second bacterium through a bacteriophage and specialized transduction, which is the process of moving restricted bacterial genes to a recipient bacterium. While generalized transduction can occur randomly and more easily, specialized transduction depends on the location of the genes on the chromosome and the incorrect excision of the a prophage.
transfectionTransfection is the process of deliberately introducing naked or purified nucleic acids into eukaryoticcells. It may also refer to other methods and cell types, although other terms are often preferred: "transformation" is typically used to describe non-viral DNA transfer in bacteria and non-animal eukaryotic cells, including plant cells. In animal cells, transfection is the preferred term as transformation is also used to refer to progression to a cancerous state (carcinogenesis) in these cells. Transduction is often used to describe virus-mediated gene transfer into eukaryotic cells. (W)
Electroporator with square wave and exponential decay waveforms for in vitro, in vivo, adherent cell and 96 well electroporation applications. Manufactured by BTX Harvard Apparatus, Holliston MA USA.
transformation (genetics)
In molecular biology and genetics,transformation is the genetic alteration of a cell resulting from the direct uptake and incorporation of exogenous genetic material from its surroundings through the cell membrane(s). For transformation to take place, the recipient bacterium must be in a state of competence, which might occur in nature as a time-limited response to environmental conditions such as starvation and cell density, and may also be induced in a laboratory.
Transformation is one of three processes for horizontal gene transfer, in which exogenous genetic material passes from one bacterium to another, the other two being conjugation (transfer of genetic material between two bacterial cells in direct contact) and transduction (injection of foreign DNA by a bacteriophage virus into the host bacterium). In transformation, the genetic material passes through the intervening medium, and uptake is completely dependent on the recipient bacterium. (W)
In this image, a gene from bacterial cell 1 is moved from bacterial cell 1 to bacterial cell 2. This process of bacterial cell 2 taking up new genetic material is called transformation.
Bacterial Transformation In this diagram, a gene from bacterial cell 1 is moved from bacterial cell 1 to bacterial cell 2. This process of bacterial cell 2 taking up new genetic material is called transformation. Step I: The DNA of a bacterial cell is located in the cytoplasm (1), but also in the plasmid, an independent, circular loop of DNA. The gene to be transferred (4) is located on the plasmid of cell 1 (3), but not on the plasmid of bacterial cell 2 (2). In order to remove the gene from the plasmid of bacterial cell 1, a restriction enzyme (5) is used. The restriction enzyme binds to a specific site on the DNA and “cuts” it, releasing the satisfactory gene. Genes are naturally removed and released into the environment usually after a cell dies and disintegrates. Step II: Bacterial cell 2 takes up the gene. This integration of genetic material from the environment is an evolutionary tool and is common in bacterial cells. Step III: The enzyme DNA ligase (6) adds the gene to the plasmid of bacterial cell 2 by forming chemical bonds between the two segments which join them together. Step IV: The plasmid of bacterial cell 2 now contains the gene from bacterial cell 1 (7). The gene has been transferred from one bacterial cell to another, and transformation is complete. (W)
Schematic of bacterial transformation – for which artificial competence must first be induced.
(1)Before it is transformed a bacterium is susceptible to antibiotics. A plasmid can be inserted when the bacteria is under stress, and be incorporated into the bacterial DNA creating antibiotic resistance. (2)When the plasmids are prepared they are inserted into the bacterial cell by either making pores in the plasma membrane with temperature extremes and chemical treatments, or making it semi permeable through the process of electrophoresis, in which electric currents create the holes in the membrane. After conditions return to normal the holes in the membrane close and the plasmids are trapped inside the bacteria where they become part of the genetic material(3). Their genes are then expressed by the bacteria(4). Reference website:http://www.odec.ca/projects/2006/sidh6h2/bg.html.(W)
transgene
A transgene is a gene that has been transferred naturally, or by any of a number of genetic engineering techniques from one organism to another. The introduction of a transgene, in a process known as transgenesis, has the potential to change the phenotype of an organism. Transgene describes a segment of DNA containing a gene sequence that has been isolated from one organism and is introduced into a different organism. This non-native segment of DNA may either retain the ability to produce RNA or protein in the transgenic organism or alter the normal function of the transgenic organism's genetic code. In general, the DNA is incorporated into the organism's germ line. For example, in higher vertebrates this can be accomplished by injecting the foreign DNA into the nucleus of a fertilized ovum. This technique is routinely used to introduce human disease genes or other genes of interest into strains of laboratory mice to study the function or pathology involved with that particular gene. (W)
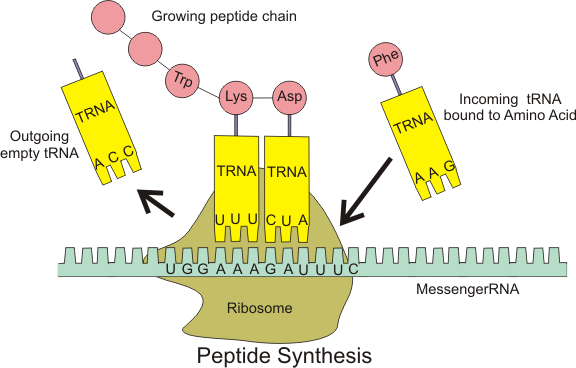
In translation, messenger RNA (mRNA) is decoded in a ribosome, outside the nucleus, to produce a specific amino acid chain, or polypeptide. The polypeptide later folds into an active protein and performs its functions in the cell. The ribosome facilitates decoding by inducing the binding of complementarytRNAanticodon sequences to mRNA codons. The tRNAs carry specific amino acids that are chained together into a polypeptide as the mRNA passes through and is "read" by the ribosome.
Translation proceeds in three phases:
Initiation: The ribosome assembles around the target mRNA. The first tRNA is attached at the start codon.
Elongation: The tRNA transfers an amino acid to the tRNA corresponding to the next codon. The ribosome then moves (translocates) to the next mRNA codon to continue the process, creating an amino acid chain.
Termination: When a stop codon is reached, the ribosome releases the polypeptide. (W)
Diagram showing the translation of mRNA and the synthesis of proteins by a ribosome.
Overview of the translation of eukaryotic messenger RNA (L)
🔎
The first step in translation, initiation, begins when an mRNA binds to a free light ribosomal subunit. A transfer RNA molecule then brings the first amino acid to the light subunit of the ribosome. Other protein factors join this assemblage and then the heavy ribosomal subunit binds to complete initiation.
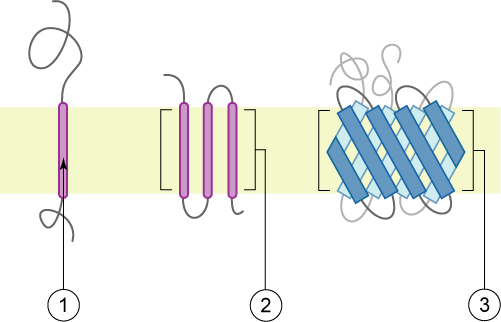
transmembrane domainTransmembrane domain usually denotes a transmembrane segment of single alpha helix of a transmembrane protein. More broadly, a transmembrane domain is any membrane-spanning protein domain.(W)
Schematic representation of transmembrane proteins: 1) a single transmembrane α-helix (bitopic membrane protein). 2) a polytopic transmembrane α-helical protein. 3) a polytopic transmembrane β-sheet protein. The membrane is represented in light yellow.
Group I and II transmembrane proteins have opposite final topologies. Group I proteins have the N terminus on the far side and C terminus on the cytosolic side. Group II proteins have the C terminus on the far side and N terminus in the cytosol. However final topology not the only criterion for defining transmembrane protein groups, rather location of topogenic determinants and mechanism of assembly is considered in the classification.
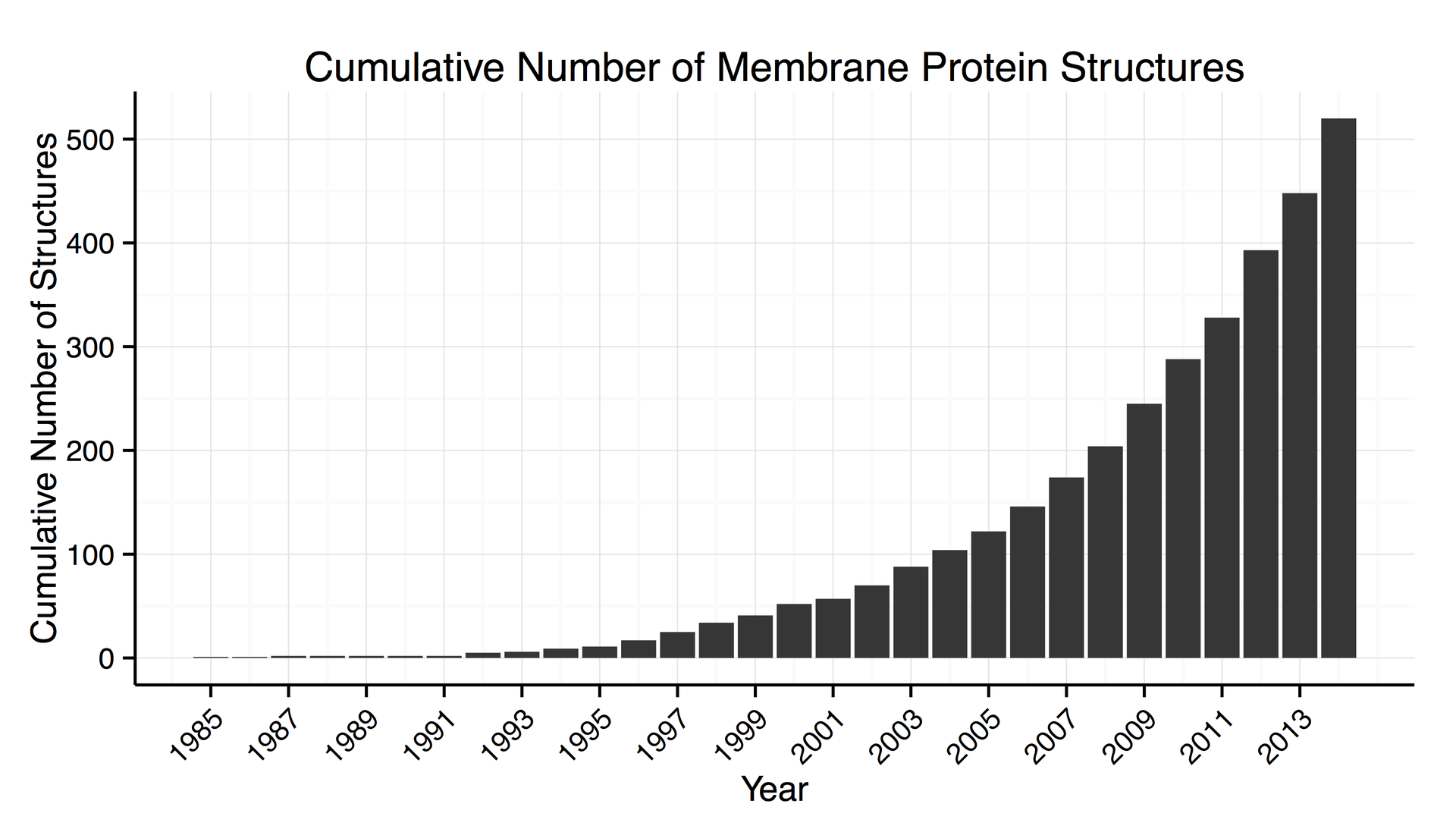
Increase in the number of 3D structures of membrane proteins known.
transmission electron microscopy DNA sequencing
Transmission electron microscopy DNA sequencing is a single-molecule sequencing technology that uses transmission electron microscopy techniques. The method was conceived and developed in the 1960s and 70s, but lost favor when the extent of damage to the sample was recognized.
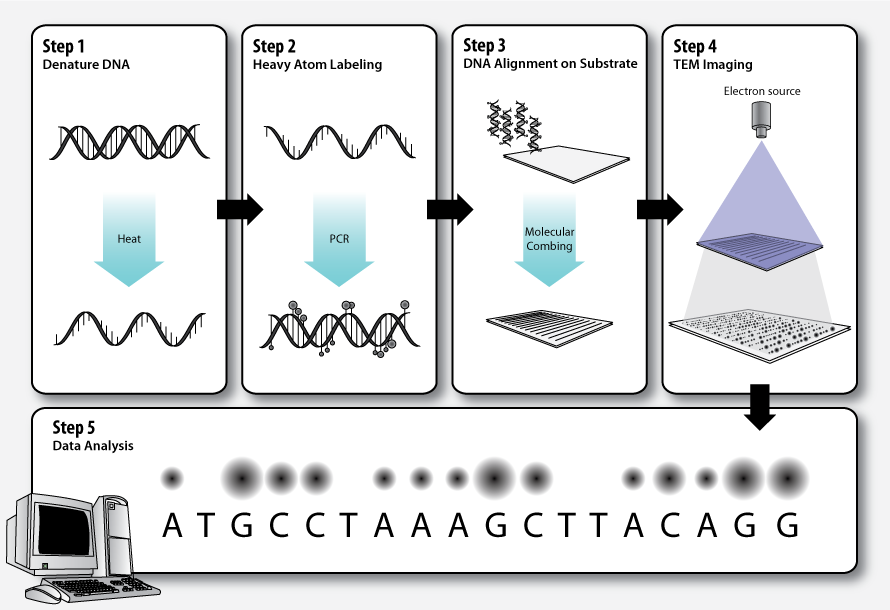
In order for DNA to be clearly visualized under an electron microscope, it must be labeled with heavy atoms. In addition, specialized imaging techniques and aberration corrected optics are beneficial for obtaining the resolution required to image the labeled DNA molecule. In theory, transmission electron microscopy DNA sequencing could provide extremely long read lengths, but the issue of electron beam damage may still remain and the technology has not yet been commercially developed. (W)
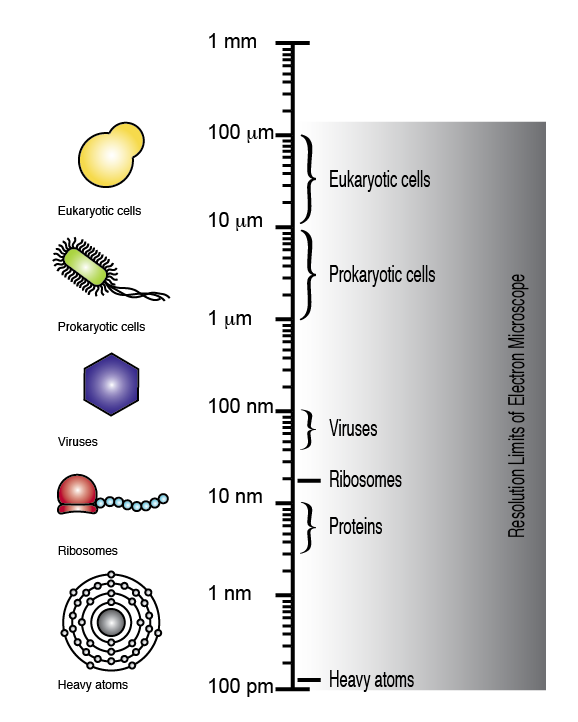
The electron microscope can achieve a resolution of up to 100 picometers, allowing eukaryotic cells, prokaryotic cells, viruses, ribosomes, and even single atoms to be visualized (note the logarithmic scale).
Workflow of transmission electron microscopy DNA sequencing.
Electron microscopy image of DNA: ribosomal transcription units of Chironomus pallidivitatus. This image was recorded with relatively old technology (ca. 2005).
Elektronenmikroskopische Aufnahme ribosomaler Transkriptionseinheiten von Chironomus pallidivitatus. Vergrößerung: 40.000x.
transposable element
A transposable element (TE,transposon, or jumping gene) is a DNA sequencethat can change its position within a genome,sometimes creating or reversing mutations and altering the cell's genetic identity and genome size. Transposition often results in duplication of the same genetic material. Barbara McClintock's discovery of them earned her a Nobel Prize in 1983.
Transposable elements make up a large fraction of the genome and are responsible for much of the mass of DNA in a eukaryotic cell. Although TEs are selfish genetic elements, many are important in genome function and evolution. Transposons are also very useful to researchers as a means to alter DNA inside a living organism.
There are at least two classes of TEs: Class I TEs or retrotransposons generally function via reverse transcription, while Class II TEs or DNA transposons encode the protein transposase, which they require for insertion and excision, and some of these TEs also encode other proteins. (W)
A bacterial DNA transposon.
A. Structure of DNA transposons (Mariner type). Two inverted tandem repeats (TIR) flank the transposase gene. Two short tandem site duplications (TSD) are present on both sides of the insert. B. Mechanism of transposition: Two transposases recognize and bind to TIR sequences, join together and promote DNA double-strand cleavage. The DNA-transposase complex then inserts its DNA cargo at specific DNA motifs elsewhere in the genome, creating short TSDs upon integration
triglyceride
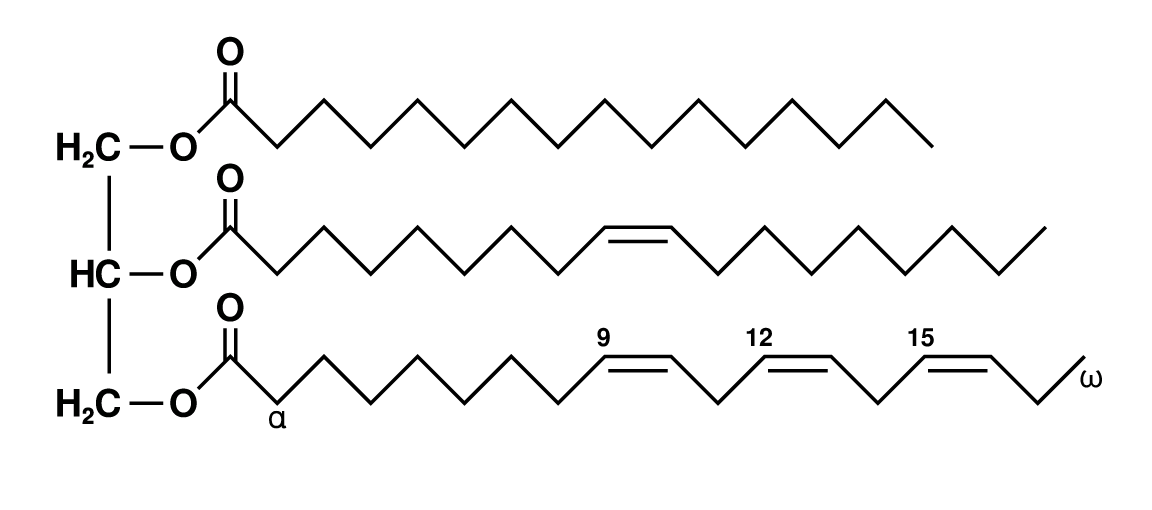
A triglyceride (TG, triacylglycerol, TAG, or triacylglyceride) is an ester derived from glycerol and three fatty acids (from tri- and glyceride). Triglycerides are the main constituents of body fat in humans and other vertebrates, as well as vegetable fat. They are also present in the blood to enable the bidirectional transference of adipose fat and blood glucose from the liver, and are a major component of human skin oils.
Many types of triglycerides exist. One classification focuses on saturated and unsaturated types. Saturated fats lack C=C groups. Unsaturated fats feature one or more C=C groups. Unsaturated fats tend to have a lower melting point than saturated analogues. Unsaturated fats often are liquid at room temperature. (W)
Trinucleotide repeat disorders, also known as microsatellite expansion diseases, are a set of over 50 genetic disorders caused by trinucleotide repeat expansion, a kind of mutation in which repeats of three nucleotides (trinucleotide repeats) increase in copy numbers until they cross a threshold above which they become unstable. Depending on where it is located, the unstable trinucleotide repeat may cause defects in a protein encoded by a gene, change the regulation of gene expression, produce a toxic RNA, or lead to chromosome instability. In general, the larger the expansion the faster the onset of disease, and the more severe the disease becomes.
Trinucleotide repeats are a subset of a larger class of unstable microsatellite repeats that occur throughout all genomes.(W)
tRNA
A transfer RNA (abbreviated tRNA and formerly referred to as sRNA, for soluble RNA) is an adaptor molecule composed of RNA, typically 76 to 90 nucleotides in length, that serves as the physical link between the mRNA and the amino acid sequence of proteins. Transfer RNA does this by carrying an amino acid to the protein synthetic machinery of a cell (ribosome) as directed by the complementary recognition of a 3-nucleotide sequence (codon) in a messenger RNA (mRNA) by a 3-nucleotide sequence (anticodon) of the tRNA. As such, tRNAs are a necessary component of translation, the biological synthesis of new proteins in accordance with the genetic code.(W)
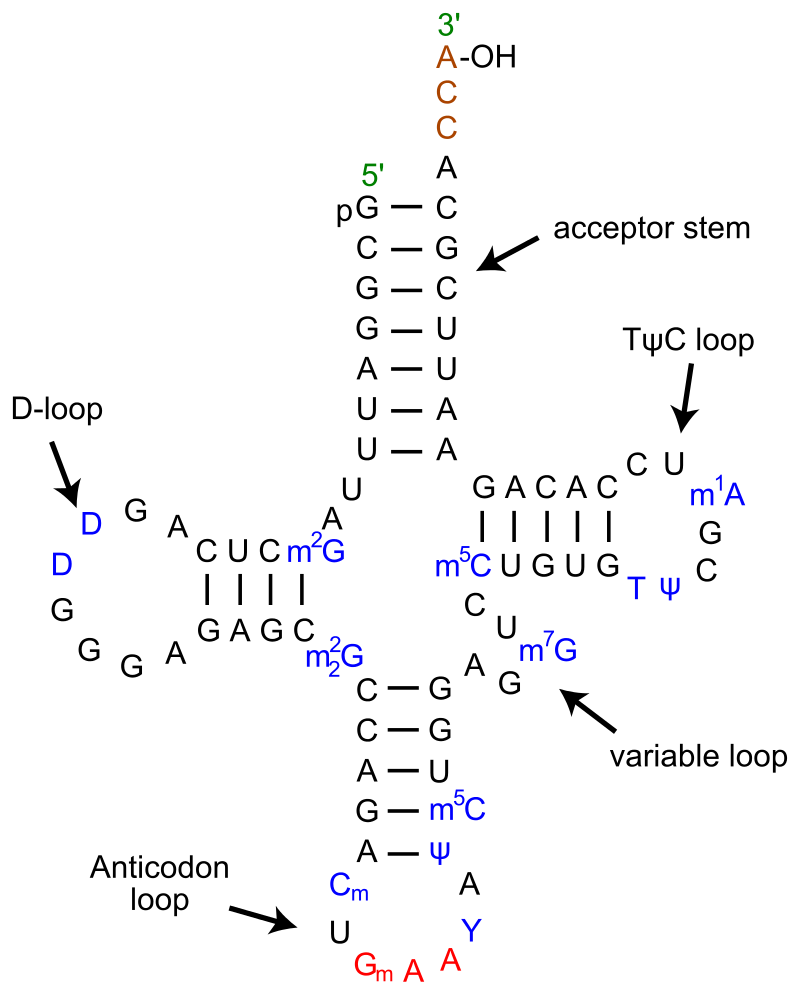
Secondary cloverleaf structure of tRNAPHe from yeast.
tRNA-Phe from yeast showing also modified bases in blue m2G: 2-methyl-guanosine D: 5,6-Dihydrouridine m22G: N2-dimethylguanosine Cm: O2'-methyl-cytdine Gm: O2'-methyl-guanosine T: 5-Methyluridine (Ribothymidine) Y: wybutosine (Y-base) Ψ: pseudouridine m5C: 5-methyl-cytidine m7G: 7-methyl-guanosine m1A: 1-methyl-adenosine.
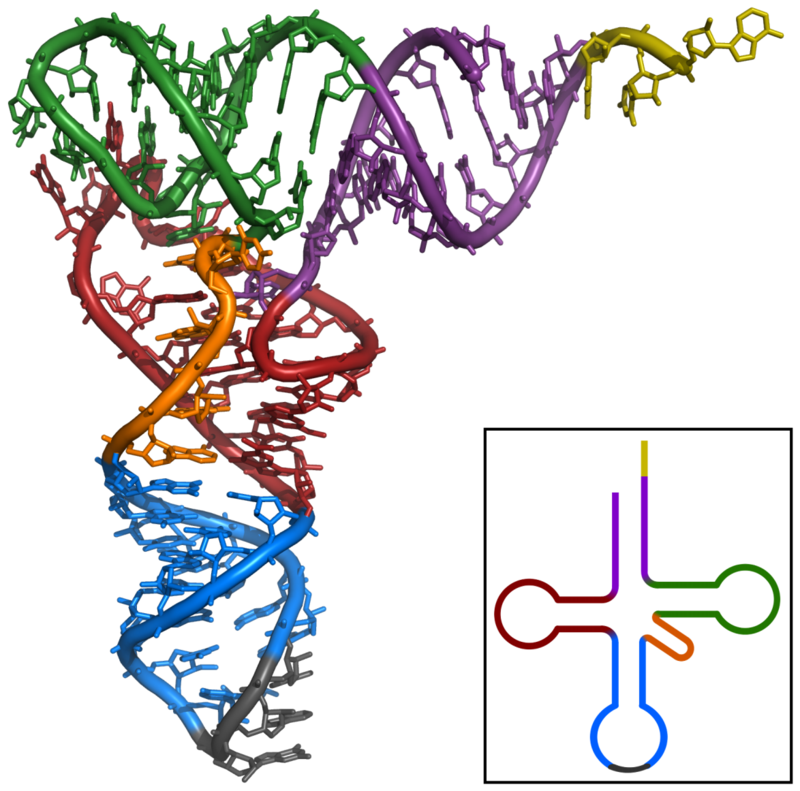
Tertiary structure of tRNA. CCA tail in yellow, Acceptor stem in purple, Variable loop in orange, D arm in red, Anticodon arm in blue with Anticodon in black, T arm in green..
X-ray structure of the tRNA
Phe
from yeast. Data was obtained by PDB: 1ehz and rendered with PyMOL. violet: acceptor stem wine red: D-loop blue: anticodon loop orange: variable loop green: TPsiC-loop yellow: CCA-3' of the acceptor stem grey: anticodon
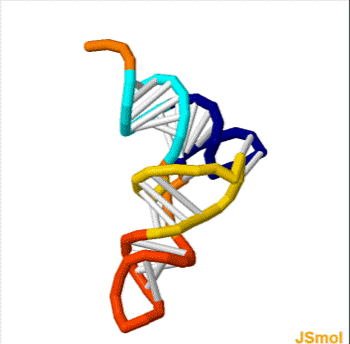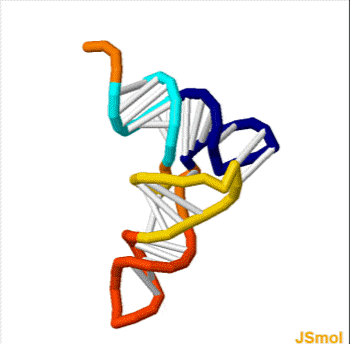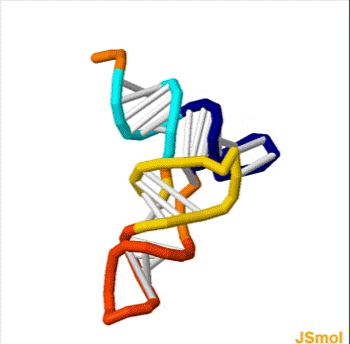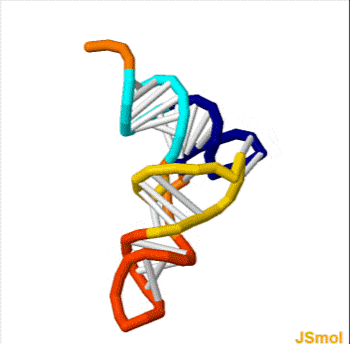
3D animated GIF showing the structure of phenylalanine-tRNA from yeast (PDB ID 1ehz). White lines indicate base pairing by hydrogen bonds. In the orientation shown, the acceptor stem is on top and the anticodon on the bottom.
📹 The Role of tRNA in Protein Synthesis / blausen (LINK)
📌 TRANSCRIPTION
For each possible triplet combination, there is a specific tRNA that will bind to it. Amino acids floating in the cytoplasm are picked up by tRNA molecules and delivered to the ribosomes. An amino acid attaches to one end of the transfer RNA molecule, while on the other end are three exposed bases. Because these bases attach, in complementary fashion, to the three bases in an mRNA codon, this region of the tRNA molecule is called the anticodon.
twintron
In molecular biology, a twintron is an intron-within-intron excised by sequential splicing reactions. A twintron is presumably formed by the insertion of a mobile intron into an existing intron. (W)
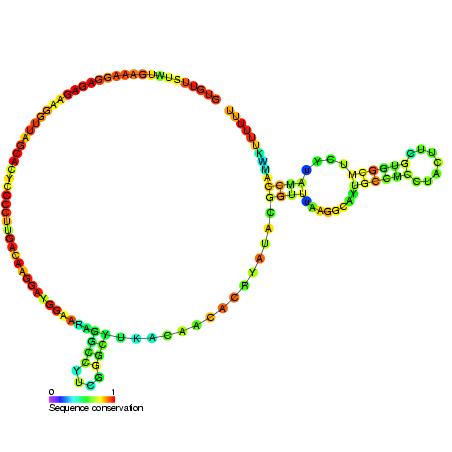
The RNA sequence of U6 is the most highly conserved across species of all five of the snRNAs involved in the spliceosome, suggesting that the function of the U6 snRNA has remained both crucial and unchanged through evolution.
It is common in vertebrate genomes to find many copies of the U6 snRNA gene or U6-derived pseudogenes. This prevalence of "back-ups" of the U6 snRNA gene in vertebrates further implies its evolutionary importance to organism viability.
The structure and catalytic mechanism of U6 snRNA resembles that of domain V of group II introns. The formation of the triple helix in U6 snRNA is deemed to be important in splicing activity, where its role is to bring the catalytic site to the splice site. (W)
U6atac minor spliceosomal RNA is a non-coding RNA which is an essential component of the minor U12-type spliceosome complex. The U12-type spliceosome is required for removal of the rarer class of eukaryoticintrons (AT-AC, U12-type).
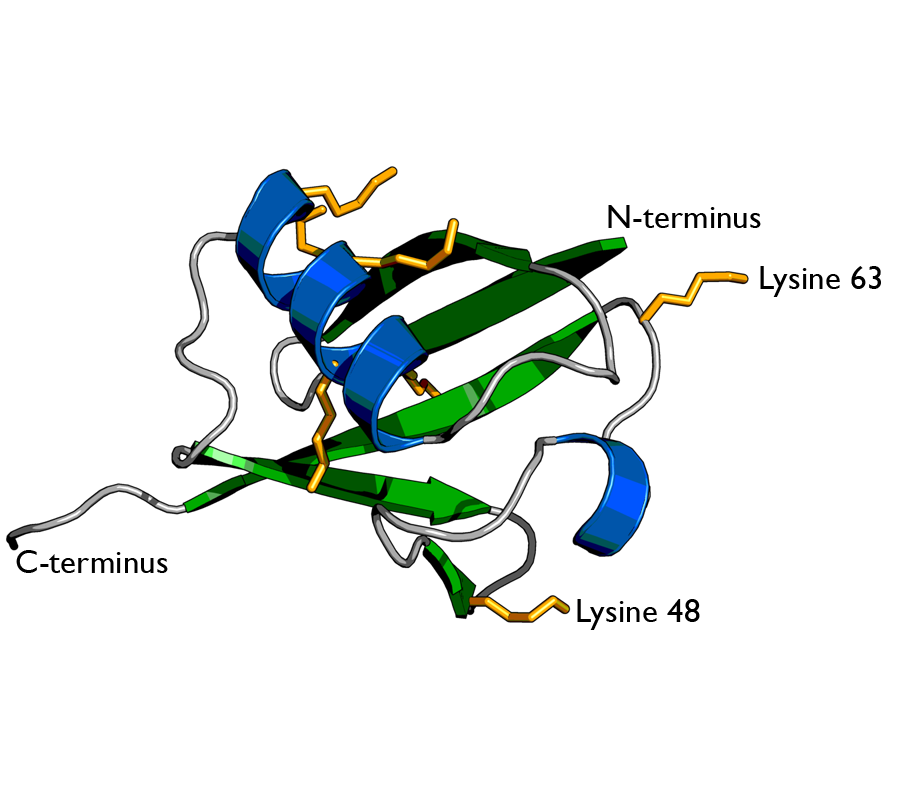
Ubiquitin is a small (8.6 kDa)regulatory protein found in most tissues of eukaryotic organisms, i.e., it is found ubiquitously. It was discovered in 1975 by Gideon Goldstein and further characterized throughout the 1970s and 1980s. Four genes in the human genome code for ubiquitin: UBB,UBC,UBA52 and RPS27A.
Cartoon representation of ubiquitin protein, highlighting the secondary structure. α-helices are coloured in blue and β-strands in green. The sidechains of the 7 lysine residues are indicated by orange sticks. The two best-characterised attachment points for further ubiquitin molecules in polyubiquitin chain formation (lysines 48 & 63) are labelled. Image was created using PyMOL from PDB id 1ubi..
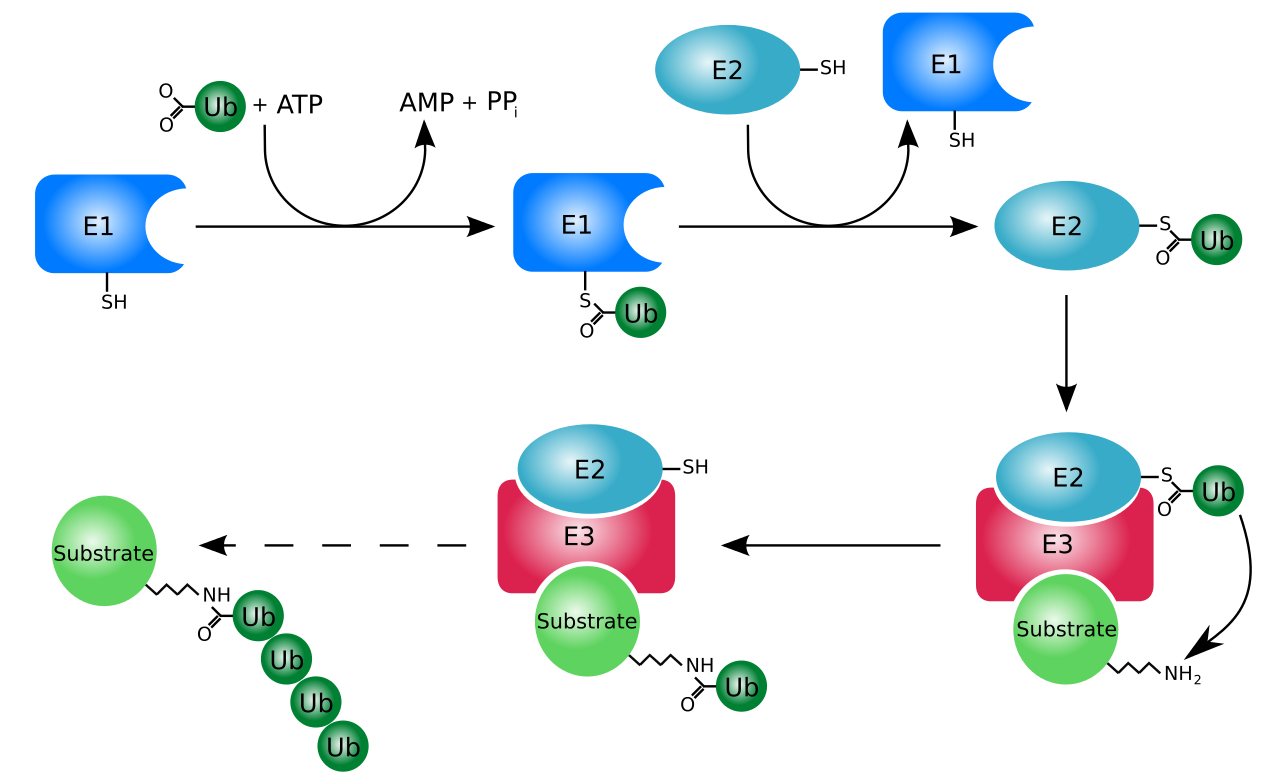
The ubiquitylation system (showing a RING E3 ligase).
untranslated region
In molecular genetics, an untranslated region (or UTR) refers to either of two sections, one on each side of a coding sequence on a strand of mRNA. If it is found on the 5' side, it is called the 5' UTR (or leader sequence), or if it is found on the 3' side, it is called the 3' UTR (or trailer sequence). mRNA is RNA that carries information from DNA to the ribosome, the site of protein synthesis (translation) within a cell. The mRNA is initially transcribed from the corresponding DNA sequence and then translated into protein. However, several regions of the mRNA are usually not translated into protein, including the 5' and 3' UTRs.
Although they are called untranslated regions, and do not form the protein-coding region of the gene, uORFs located within the 5' UTR can be translated into peptides.
The 5' UTR is upstream from the coding sequence. Within the 5' UTR is a sequence that is recognized by the ribosome which allows the ribosome to bind and initiate translation. The mechanism of translation initiation differs in prokaryotes and eukaryotes. The 3' UTR is found immediately following the translation stop codon. The 3' UTR plays a critical role in translation termination as well as post-transcriptional modification.
These often long sequences were once thought to be useless or junk mRNA that has simply accumulated over evolutionary time. However, it is now known that the untranslated region of mRNA is involved in many regulatory aspects of gene expression in eukaryotic organisms. The importance of these non-coding regions is supported by evolutionary reasoning, as natural selection would have otherwise eliminated this unusable RNA.
It is important to distinguish the 5' and 3' UTRs from other non-protein-coding RNA. Within the coding sequence of pre-mRNA, there can be found sections of RNA that will not be included in the protein product. These sections of RNA are called introns. The RNA that results from RNA splicing is a sequence of exons. The reason why introns are not considered untranslated regions is that the introns are spliced out in the process of RNA splicing. The introns are not included in the mature mRNA molecule that will undergo translation and are thus considered non-protein-coding RNA. (W)
mRNA structure, approximately to scale for a human mRNA.
Diagramatic structure of a typical human protein coding mRNA including the untranslated regions (UTRs).It is drawn approximately to scale. The cap is only one modified base, average en:5' UTR length 170, en:3' UTR 700.
upstream open reading frame
An upstream open reading frame (uORF) is an open reading frame (ORF) within the 5' untranslated region (5'UTR) of an mRNA. uORFs can regulate eukaryoticgene expression. Translation of the uORF typically inhibits downstream expression of the primary ORF. In bacteria, uORFs are called leader peptides and were originally discovered on the basis of their impact on the regulation of genes involved in the synthesis or transport of amino acids.
Approximately 50% of human genes contain uORFs in their 5'UTR, and when present, these cause reductions in protein expression. Human peptides derived from translated uORFs can be detected from cellular material with a mass spectrometer.(W)
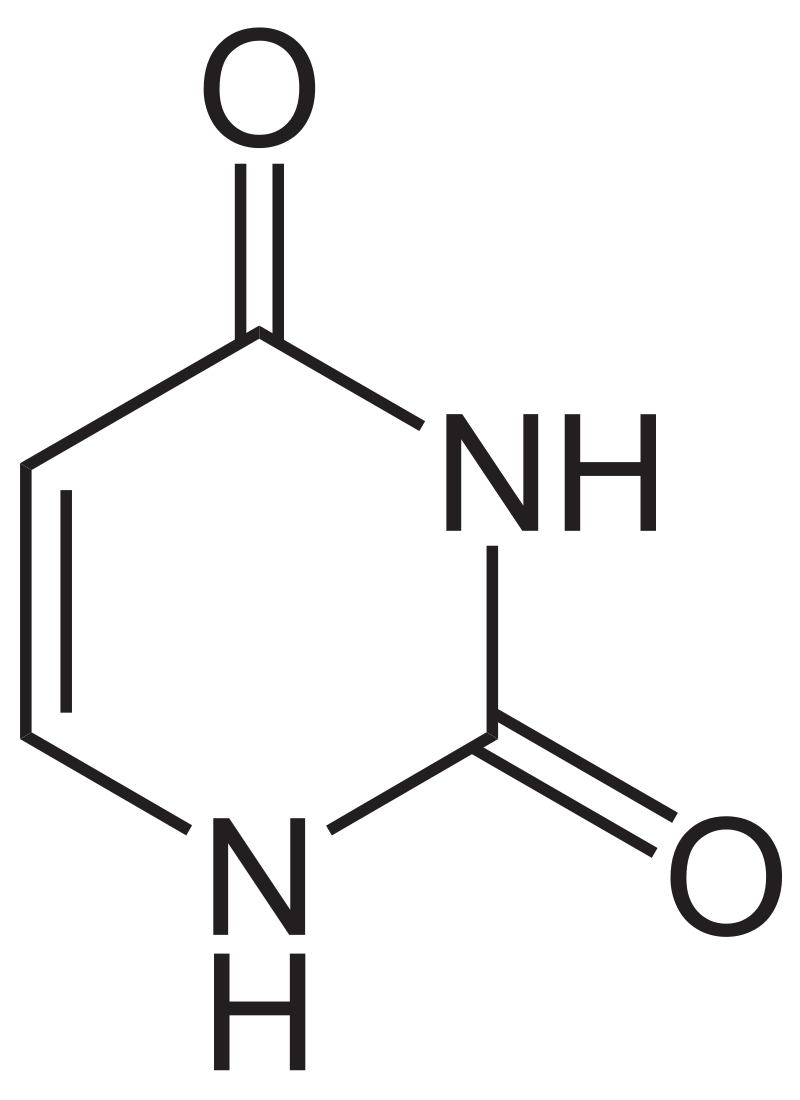
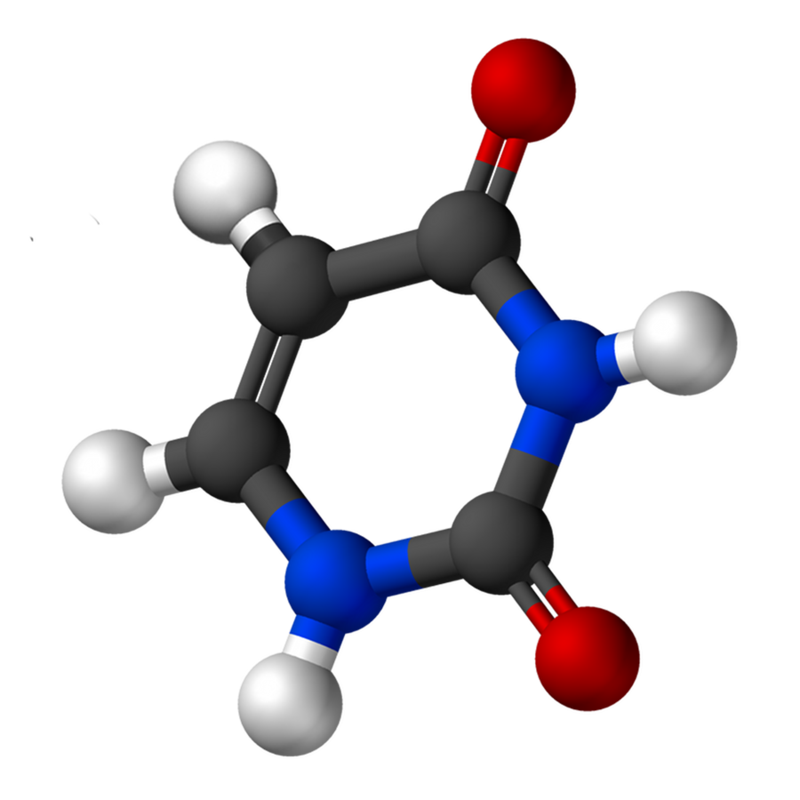
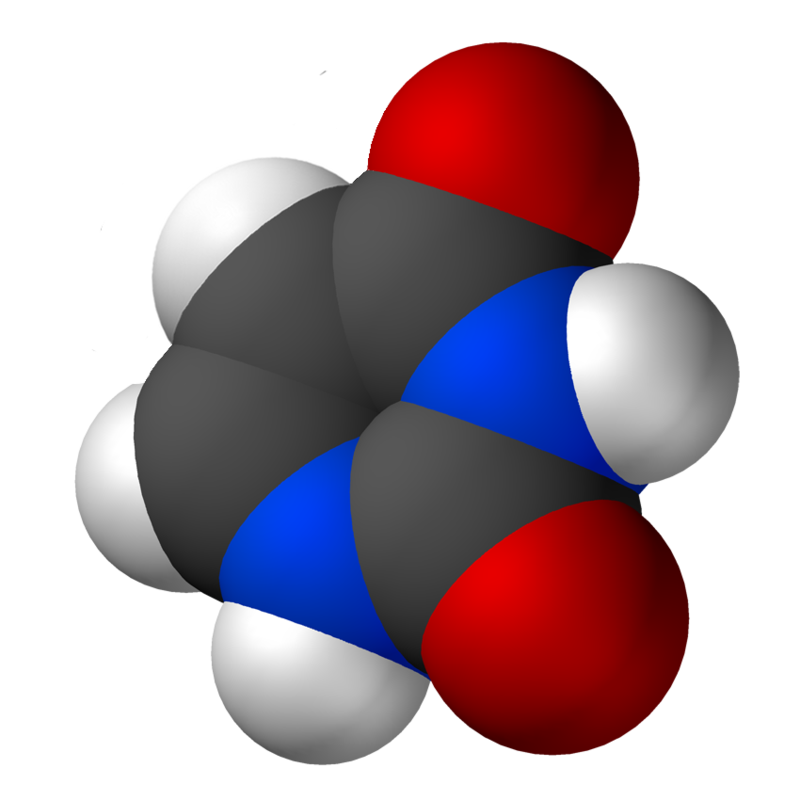
Uracil is a common and naturally occurring pyrimidine derivative. The name "uracil" was coined in 1885 by the German chemist Robert Behrend, who was attempting to synthesize derivatives of uric acid. Originally discovered in 1900 by Alberto Ascoli, it was isolated by hydrolysis of yeastnuclein; it was also found in bovinethymus and spleen,herringsperm, and wheatgerm. It is a planar, unsaturated compound that has the ability to absorb light.
In 2012, an analysis of data from the Cassini mission orbiting in the Saturn system showed that Titan's surface composition may include uracil. (W)
Structural formula of uracil.
Ball-and-stick model of uracil.
Space-filling model of uracil.
v
VA RNA
The VA (viral associated) RNA is a type of non-coding RNA found in adenovirus. It plays a role in regulating translation. There are two copies of this RNA called VAI or VA RNAI and VAII or VA RNAII. These two VA RNA genes are distinct genes in the adenovirus genome. VA RNAI is the major species with VA RNAII expressed at a lower level. Neither transcript is polyadenylated and both are transcribed by PolIII. W)
Many eukaryotic cells contain large ribonucleoprotein particles in the cytoplasm known as vaults. The vault complex comprises the major vault protein (MVP), two minor vault proteins (VPARP and TEP1), and a variety of small untranslated RNA molecules. Given the association with the nuclear membrane and the location within the cell, vaults are thought to play roles in intracellular and nucleocytoplasmic transport processes. Also, given that the structure and protein composition are highly conserved among species, it is believed that the roles vault plays are integral to eukaryotic function.
While vault proteins appear to be present in a variety of organisms, vaults isolated from higher eukaryotes contain a small portion, about 5%, of small untranslated RNAs called vault RNAs, or vtRNAs. These RNA molecules are polymerase III transcripts. In addition, a study, using cryo-electron microscopy, has determined that vtRNAs are found close to the end caps of vaults. This positioning of the RNA indicates that they could interact with both the interior and exterior of the vault particle. Overall, the current belief is that the vtRNAs do not have a structural role in the vault protein, but rather play some kind of functional role. However, while there has been an expanding body of research on vtRNA, there has yet to be a solid conclusion on the exact function. (W)
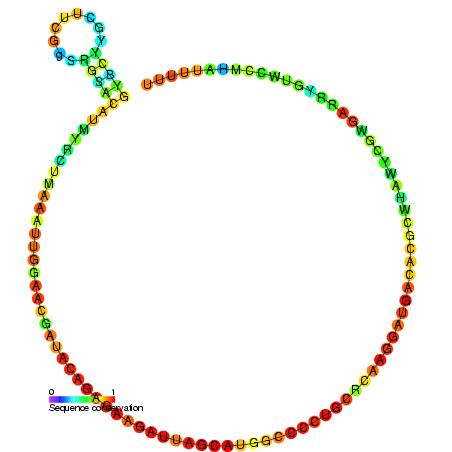
Homo sapiens vault associated RNA folded at 37° C. The sequence has 98 base pairs. The accession number retrieved from the NCBI database is AF045143. The sequence was fed into a DNA and RNA folding web program called "The mfold web server" through The RNA Institute College of Arts and Sciences at the University of Albany.
viral replicationViral replication is the formation of biological viruses during the infection process in the target host cells. Viruses must first get into the cell before viral replication can occur. Through the generation of abundant copies of its genome and packaging these copies, the virus continues infecting new hosts. Replication between viruses is greatly varied and depends on the type of genes involved in them. Most DNA viruses assemble in the nucleus while most RNA viruses develop solely in cytoplasm. (W)
A diagram of influenza viral cell invasion and replication.
Viral transformation is the change in growth, phenotype, or indefinite reproduction of cells caused by the introduction of inheritable material. Through this process, a virus causes harmful transformations of an in vivo cell or cell culture. The term can also be understood as DNA transfection using a viral vector.
Viral transformation can occur both naturally and medically. Natural transformations can include viral cancers, such as human papillomavirus (HPV) and T-cell Leukemia virus type I. Hepatitis B and C are also the result of natural viral transformation of the host cells. Viral transformation can also be induced for use in medical treatments.
Cells that have been virally transformed can be differentiated from untransformed cells through a variety of growth, surface, and intracellular observations. The growth of transformed cells can be impacted by a loss of growth limitation caused by cell contact, less oriented growth, and high saturation density. Transformed cells can lose their tight junctions, increase their rate of nutrient transfer, and increase their protease secretion. Transformation can also affect the cytoskeleton and change in the quantity of signal molecules. (W)
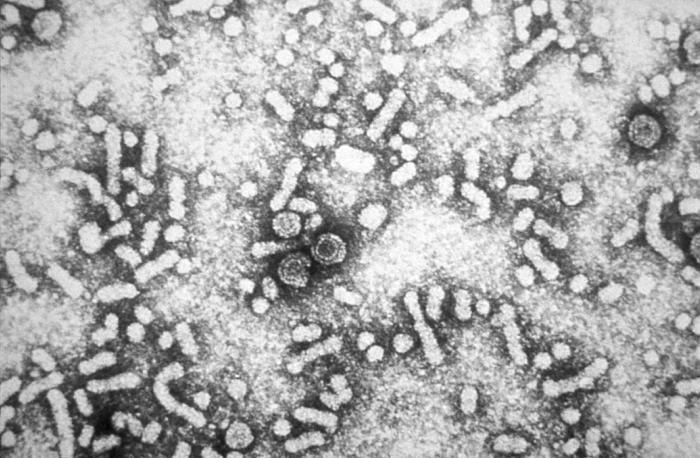
Figure 1: Hepatitis-B virions..
This electron micrograph reveals the presence of hepatitis-B virus HBV "Dane particles", or virions. The infective hepatitis-B (HBV), virions are also known as Dane particles. These particles measure 42nm in their overall diameter, and contain a DNA-based core that is 27nm in diameter.
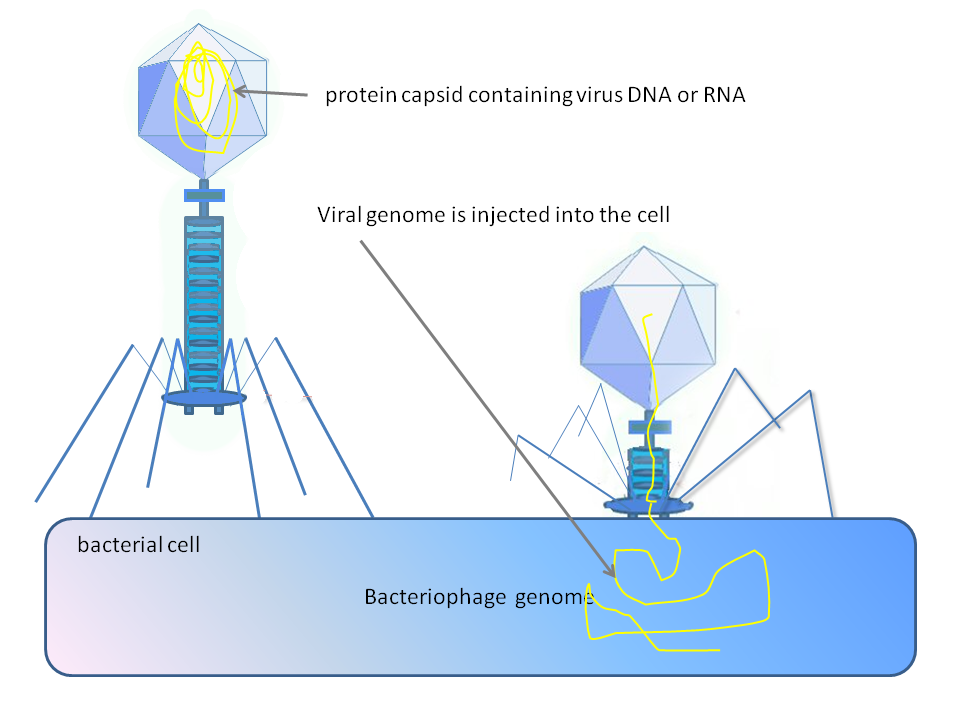
Figure 2: Phage injecting its genome into bacterial cell.
Diagram of how some bacteriophages infect cells: this is not drawn to scale, bacteriophages are about 100 x smaller than bacteria.
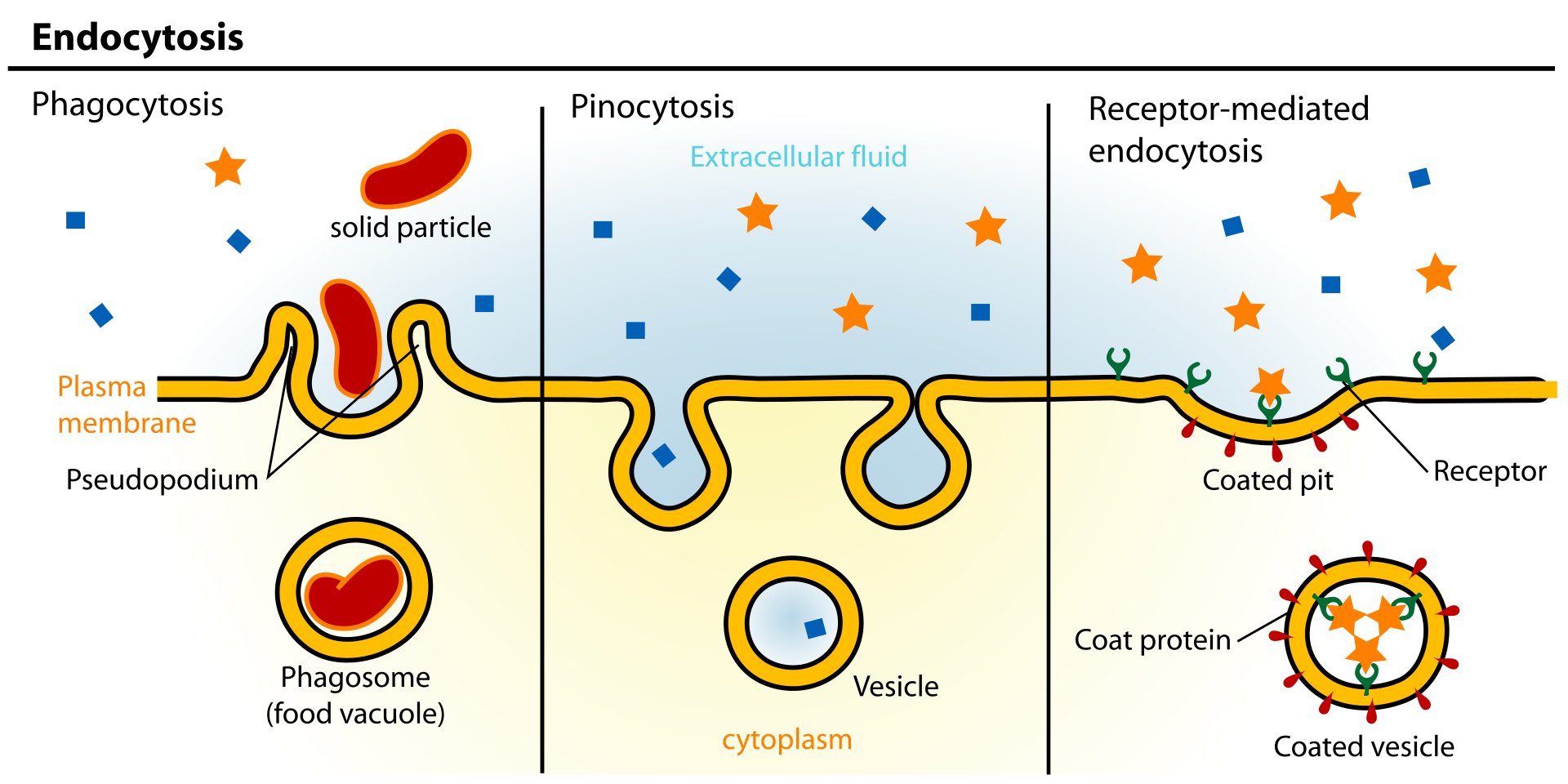
Figure 3: Examples of endocytosis.
Endocytosis is a process whereby cells absorb material (molecules such as proteins) from the outside by engulfing it with their cell membrane. It is used by all cells of the body because most substances important to them are polar and consist of big molecules, and thus cannot pass through the hydrophobic plasma membrane..
Figure 4: Type I Human Interferon.
viral vector
Viral vectors are tools commonly used by molecular biologists to deliver genetic material into cells. This process can be performed inside a living organism (in vivo) or in cell culture (in vitro). Viruses have evolved specialized molecular mechanisms to efficiently transport their genomes inside the cells they infect. Delivery of genes, or other genetic material, by a vector is termed transduction and the infected cells are described as transduced. Molecular biologists first harnessed this machinery in the 1970s. Paul Berg used a modified SV40 virus containing DNA from the bacteriophageλ to infect monkey kidney cells maintained in culture.
In addition to their use in molecular biology research, viral vectors are used for gene therapy and the development of vaccines. (W)
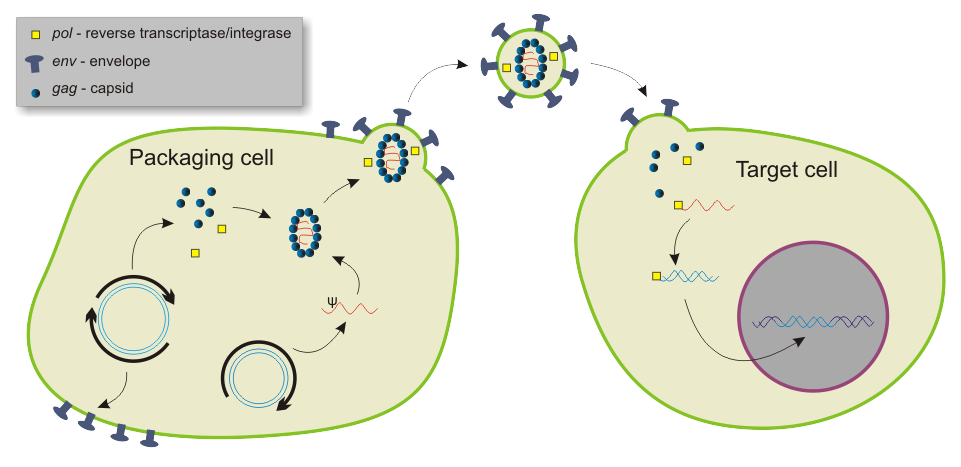
Packaging and transduction by a lentiviral vector..
viroid
Viroids are the smallest infectious pathogens known. They are composed solely of a short strand of circular, single-stranded RNA that has no protein coating. All known viroids are inhabitants of higher plants, and most cause diseases, whose respective economic importance on humans varies widely.
The first recognized viroid, the pathogenic agent of the potato spindle tuber disease, was discovered, initially molecularly characterized, and named by Theodor Otto Diener, plant pathologist at the U.S Department of Agriculture's Research Center in Beltsville, Maryland, in 1971. This viroid is now called Potato spindle tuber viroid, abbreviated PSTVd. (W)
Putative secondary structure of the PSTV (potato spindle tuber viroid) Black: secondary structure of the viroid Red: GAAAC sequence common to all viroids Yellow: central conservative sequence Blue: nucleotide numbers Sequence of the viroid: 1 CGGAACUAAA CUCGUGGUUC CUGUGGUUCA CACCUGACCU CCUGAGCAGA AAAGAAAAAA 61 GAAGGCGGCU CGGAGGAGCG CUUCAGGGAU CCCCGGGGAA ACCUGGAGCG AACUGGCAAA 121 AAAGGACGGU GGGGAGUGCC CAGCGGCCGA CAGGAGUAAU UCCCGCCGAA ACAGGGUUUU 181 CACCCUUCCU UUCUUCGGGU GUCCUUCCUC GCGCCCGCAG GACCACCCCU CGCCCCCUUU 241 GCGCUGUCGC UUCGGCUACU ACCCGGUGGA AACAACUGAA GCUCCCGAGA ACCGCUUUUU 301 CUCUAUCUUA CUUGCUUCGG GGCGAGGGUG UUUAGCCCUU GGAACCGCAG UUGGUUCCU.
The reproduction mechanism of a typical viroid. Leaf contact transmits the viroid. The viroid enters the cell via its plasmodesmata. RNA polymerase II catalyzes rolling-circle synthesis of new viroids.
viroplasm
A viroplasm, sometimes called 'virus factory' or 'virus inclusion'. is an inclusion body in a cell where viral replication and assembly occurs. They may be thought of as viral factories in the cell. There are many viroplasms in one infected cell, where they appear dense to electron microscopy. Very little is understood about the mechanism of viroplasm formation. (W)
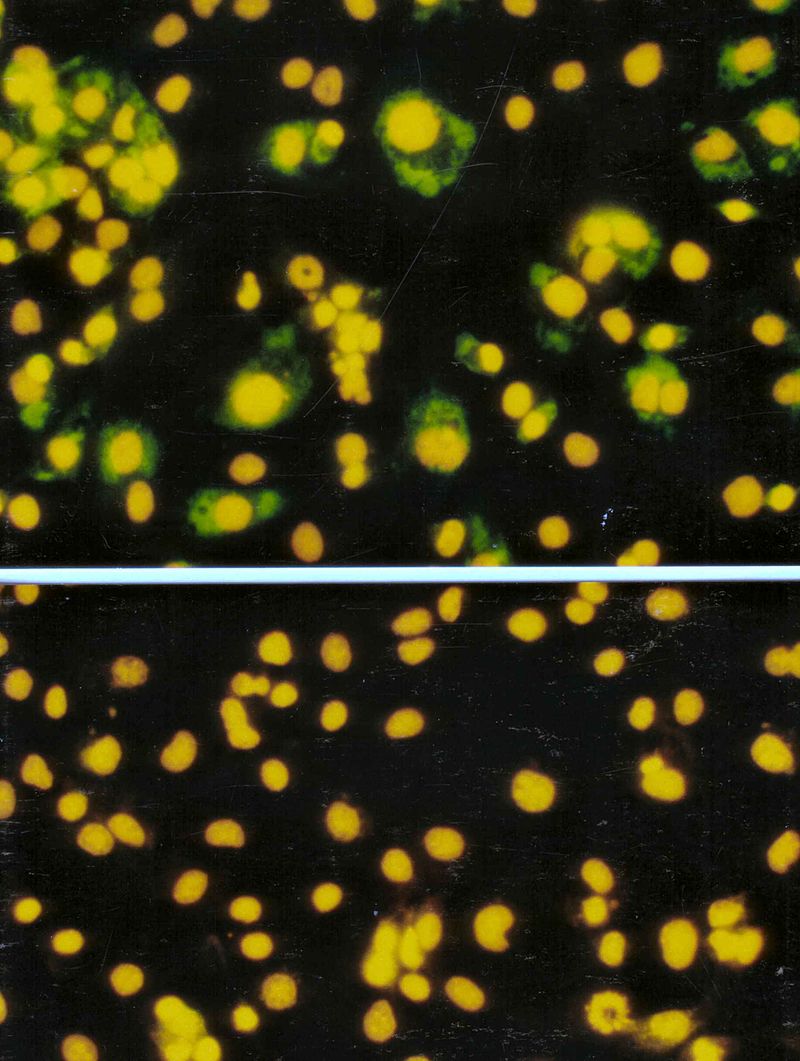
Viroplasms (green) in cells infected with rotavirus (top), and uninfected cells (bottom). (Immunofluorescent stain).
Cells infected with rotavirus (top) and labelled with a monoclonal antibody tagged with Fluorescein Isothiocyanate (FITC) compared with uninfected cells (bottom).
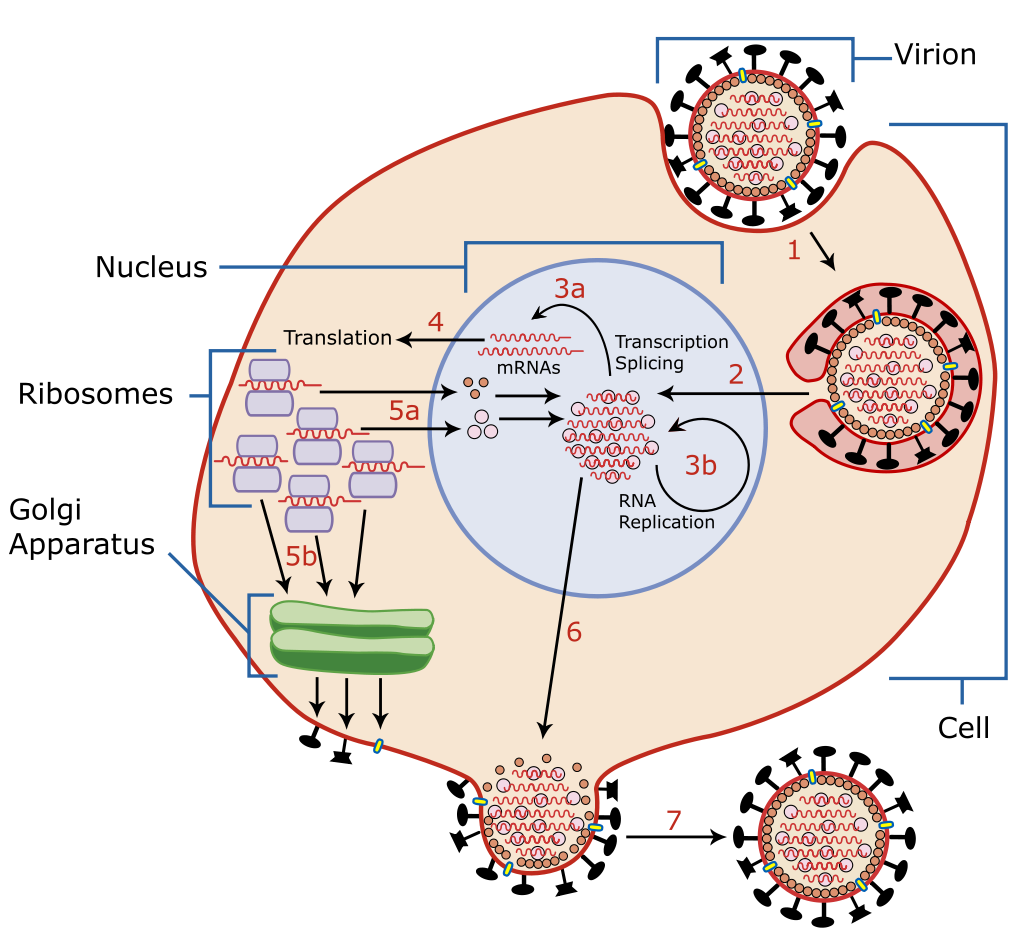
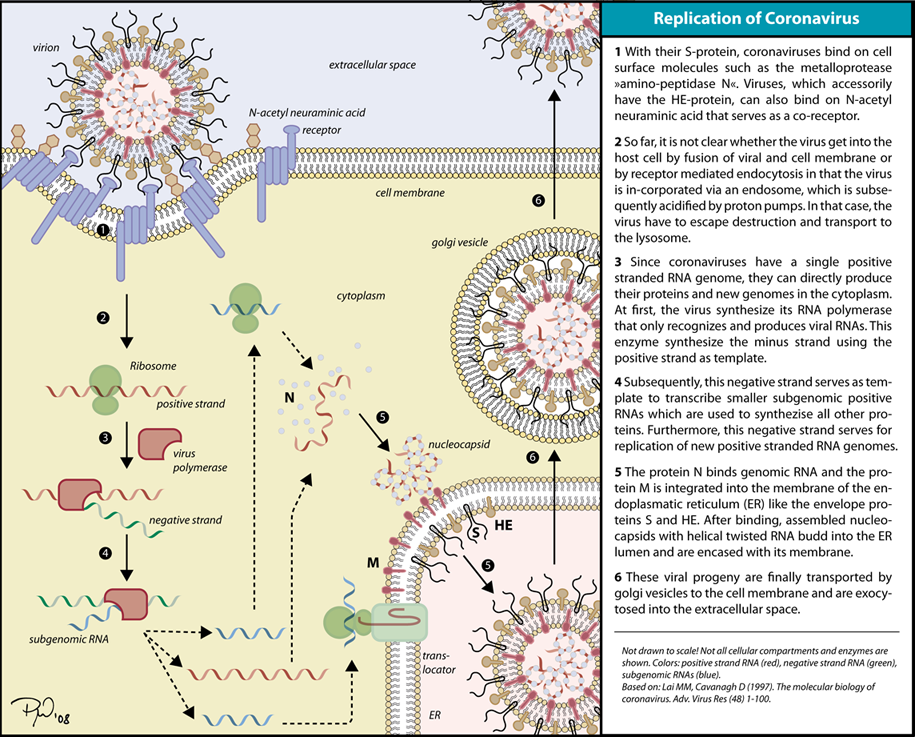
When infected, a host cell is forced to rapidly produce thousands of identical copies of the original virus. When not inside an infected cell or in the process of infecting a cell, viruses exist in the form of independent particles, or virions, consisting of: (i) the genetic material, i.e., long molecules of DNA or RNA that encode the structure of the proteins by which the virus acts; (ii) a protein coat, the capsid, which surrounds and protects the genetic material; and in some cases (iii) an outside envelope of lipids. The shapes of these virus particles range from simple helical and icosahedral forms to more complex structures. Most virus species have virions too small to be seen with an optical microscope, as they are one-hundredth the size of most bacteria.
The origins of viruses in the evolutionary history of life are unclear: some may have evolved from plasmids—pieces of DNA that can move between cells—while others may have evolved from bacteria. In evolution, viruses are an important means of horizontal gene transfer, which increases genetic diversity in a way analogous to sexual reproduction. Viruses are considered by some biologists to be a life form, because they carry genetic material, reproduce, and evolve through natural selection, although they lack the key characteristics, such as cell structure, that are generally considered necessary criteria for life. Because they possess some but not all such qualities, viruses have been described as "organisms at the edge of life", and as self-replicators.
Viruses spread in many ways. One transmission pathway is through disease-bearing organisms known as vectors: for example, viruses are often transmitted from plant to plant by insects that feed on plant sap, such as aphids; and viruses in animals can be carried by blood-sucking insects. Influenza viruses are spread by coughing and sneezing. Norovirus and rotavirus, common causes of viral gastroenteritis, are transmitted by the faecal–oral route, passed by hand-to-mouth contact or in food or water. The infectious dose of norovirus required to produce infection in humans is less than 100 particles. HIV is one of several viruses transmitted through sexual contact and by exposure to infected blood. The variety of host cells that a virus can infect is called its "host range". This can be narrow, meaning a virus is capable of infecting few species, or broad, meaning it is capable of infecting many.
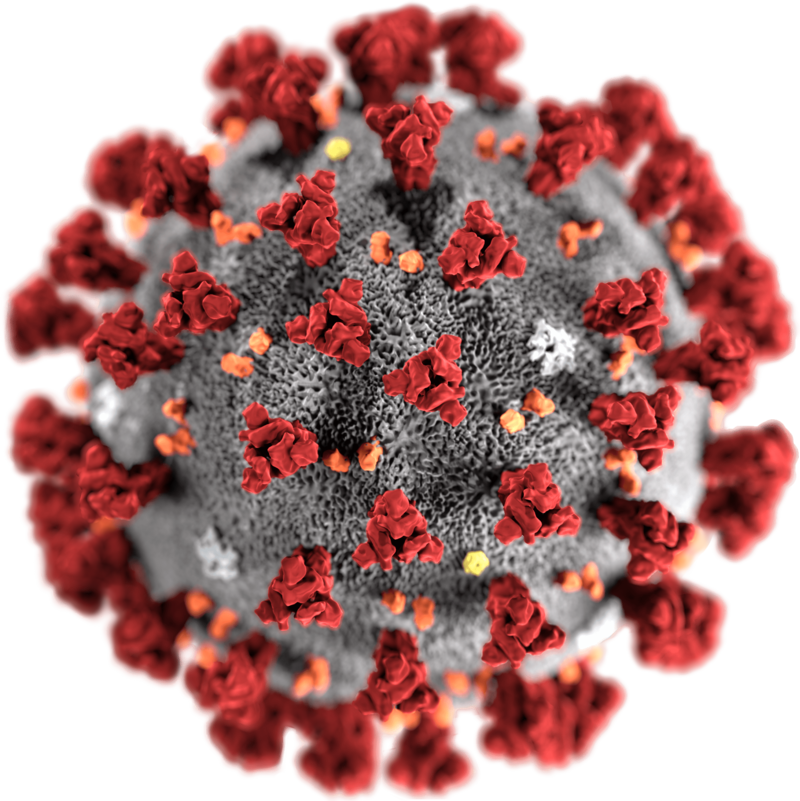
This illustration, created at the Centers for Disease Control and Prevention (CDC), reveals ultrastructural morphology exhibited by coronaviruses. Note the spikes that adorn the outer surface of the virus, which impart the look of a corona surrounding the virion, when viewed electron microscopically. A novel coronavirus, named Severe Acute Respiratory Syndrome coronavirus 2 (SARS-CoV-2), was identified as the cause of an outbreak of respiratory illness first detected in Wuhan, China in 2019. The illness caused by this virus has been named coronavirus disease 2019 (COVID-19).
Diagram of how a virus capsid can be constructed using multiple copies of just two protein molecules.
Structure of icosahedral adenovirus. Electron micrograph with an illustration to show shape.
Two adenoviruses with a cartoon to show their icosahedral structure.
Structure of chickenpox virus. They have a lipid envelope.
Electron micrograph of a Varicella (Chickenpox) Virus. Varicella or Chickenpox, is an infectious disease caused by the varicella-zoster virus, which results in a blister-like rash, itching, tiredness and fever.
Structure of an icosahedral cowpea mosaic virus.
Structure of the icosahedral Cowpea mosaic virus (CPMV) based on PDB ID 2BFU.
Bacteriophage Escherichia virus MS2 capsid. This spherical virus also has icosahedral symmetry.
Cartoon representation of the entire bacteriophage MS2 protein capsid (pdb id 1AQ3). The three quasi-equivalent conformers in the structure are labelled blue (chain a), green (chain b) and magenta (chain c). The view is approximately down an icosahedral 5-fold symmetry axis.
Some bacteriophages inject their genomes into bacterial cells (not to scale).
Diagram of how some bacteriophages infect bacterial cells (not to scale; bacteriophages are much smaller than bacteria).
Virusoids are essentially viroids that have been encapsulated by a helper virus coat protein. They are thus similar to viroids in their means of replication (rolling circle replication) and due to the lack of genes, but they differ in that viroids do not possess a protein coat. They encode a hammerhead ribozyme.
Virusoids, while being studied in virology, are subviral particles rather than viruses. Since they depend on helper viruses, they are classified as satellites. Virusoids are listed in virological taxonomy as Satellites/Satellite nucleic acids/Subgroup 3: Circular satellite RNA(s). (W)
Vitamins have diverse biochemical functions. Vitamin A acts as a regulator of cell and tissue growth and differentiation. Vitamin D provides a hormone-like function, regulating mineral metabolism for bones and other organs. The B complex vitamins function as enzyme cofactors (coenzymes) or the precursors for them. Vitamins C and E function as antioxidants. Both deficient and excess intake of a vitamin can potentially cause clinically significant illness, although excess intake of water-soluble vitamins is less likely to do so.
Before 1935, the only source of vitamins was from food. If intake of vitamins was lacking, the result was vitamin deficiency and consequent deficiency diseases. Then, commercially produced tablets of yeast-extract vitamin B complex and semi-synthetic vitamin C became available. This was followed in the 1950s by the mass production and marketing of vitamin supplements, including multivitamins, to prevent vitamin deficiencies in the general population. Governments mandated addition of vitamins to staple foods such as flour or milk, referred to as food fortification, to prevent deficiencies. Recommendations for folic acid supplementation during pregnancy reduced risk of infant neural tube defects.
The term vitamin is derived from the word vitamine, which was coined in 1912 by Polish biochemist Casimir Funk, who isolated a complex of micronutrients essential to life, all of which he presumed to be amines. When this presumption was later determined not to be true, the "e" was dropped from the name. All vitamins were discovered (identified) between 1913 and 1948. (W)
voltage-gated calcium channel
Voltage-gated calcium channels (VGCCs), also known as voltage-dependent calcium channels (VDCCs), are a group of voltage-gated ion channels found in the membrane of excitable cells (e.g., muscle, glial cells, neurons, etc.) with a permeability to the calcium ion Ca2+. These channels are slightly permeable to sodium ions, so they are also called Ca2+-Na+ channels, but their permeability to calcium is about 1000-fold greater than to sodium under normal physiological conditions.
At physiologic or resting membrane potential, VGCCs are normally closed. They are activated (i.e.: opened) at depolarized membrane potentials and this is the source of the "voltage-gated" epithet. The concentration of calcium (Ca2+ ions) is normally several thousand times higher outside the cell than inside. Activation of particular VGCCs allows a Ca2+ influx into the cell, which, depending on the cell type, results in activation of calcium-sensitive potassium channels, muscular contraction, excitation of neurons, up-regulation of gene expression, or release of hormones or neurotransmitters.
VGCCs have been immunolocalized in the zona glomerulosa of normal and hyperplastic human adrenal, as well as in aldosterone-producing adenomas (APA), and in the latter T-type VGCCs correlated with plasma aldosterone levels of patients. Excessive activation of VGCCs is a major component of excitotoxicity, as severely elevated levels of intracellular calcium activates enzymes which, at high enough levels, can degrade essential cellular structures. (W)
Whole genome sequencing is ostensibly the process of determining the complete DNA sequence of an organism's genome at a single time. This entails sequencing all of an organism's chromosomal DNA as well as DNA contained in the mitochondria and, for plants, in the chloroplast. In practice, genome sequences that are nearly complete are also called whole genome sequences.
Whole genome sequencing has largely been used as a research tool, but was being introduced to clinics in 2014. In the future of personalized medicine, whole genome sequence data may be an important tool to guide therapeutic intervention. The tool of gene sequencing at SNP level is also used to pinpoint functional variants from association studies and improve the knowledge available to researchers interested in evolutionary biology, and hence may lay the foundation for predicting disease susceptibility and drug response.
Whole genome sequencing should not be confused with DNA profiling, which only determines the likelihood that genetic material came from a particular individual or group, and does not contain additional information on genetic relationships, origin or susceptibility to specific diseases. In addition, whole genome sequencing should not be confused with methods that sequence specific subsets of the genome - such methods include whole exome sequencing (1-2% of the genome) or SNP genotyping (<0.1% of the genome). As of 2017 there were no complete genomes for any mammals, including humans. Between 4% to 9% of the human genome, mostly satellite DNA, had not been sequenced. (W)
The first bacterial whole genome to be sequenced was of the bacterium Haemophilus influenzae.
x
X-inactivation
X-inactivation (also called Lyonization, after English geneticist Mary Lyon) is a process by which one of the copies of the X chromosome is inactivated in therianfemalemammals. The inactive X chromosome is silenced by it being packaged into a transcriptionally inactive structure called heterochromatin. As nearly all female mammals have two X chromosomes, X-inactivation prevents them from having twice as many X chromosome gene products as males, who only possess a single copy of the X chromosome (see dosage compensation).
The choice of which X chromosome will be inactivated is random in placental mammals such as humans, but once an X chromosome is inactivated it will remain inactive throughout the lifetime of the cell and its descendants in the organism. Unlike the random X-inactivation in placental mammals, inactivation in marsupials applies exclusively to the paternally-derived X chromosome. (W)
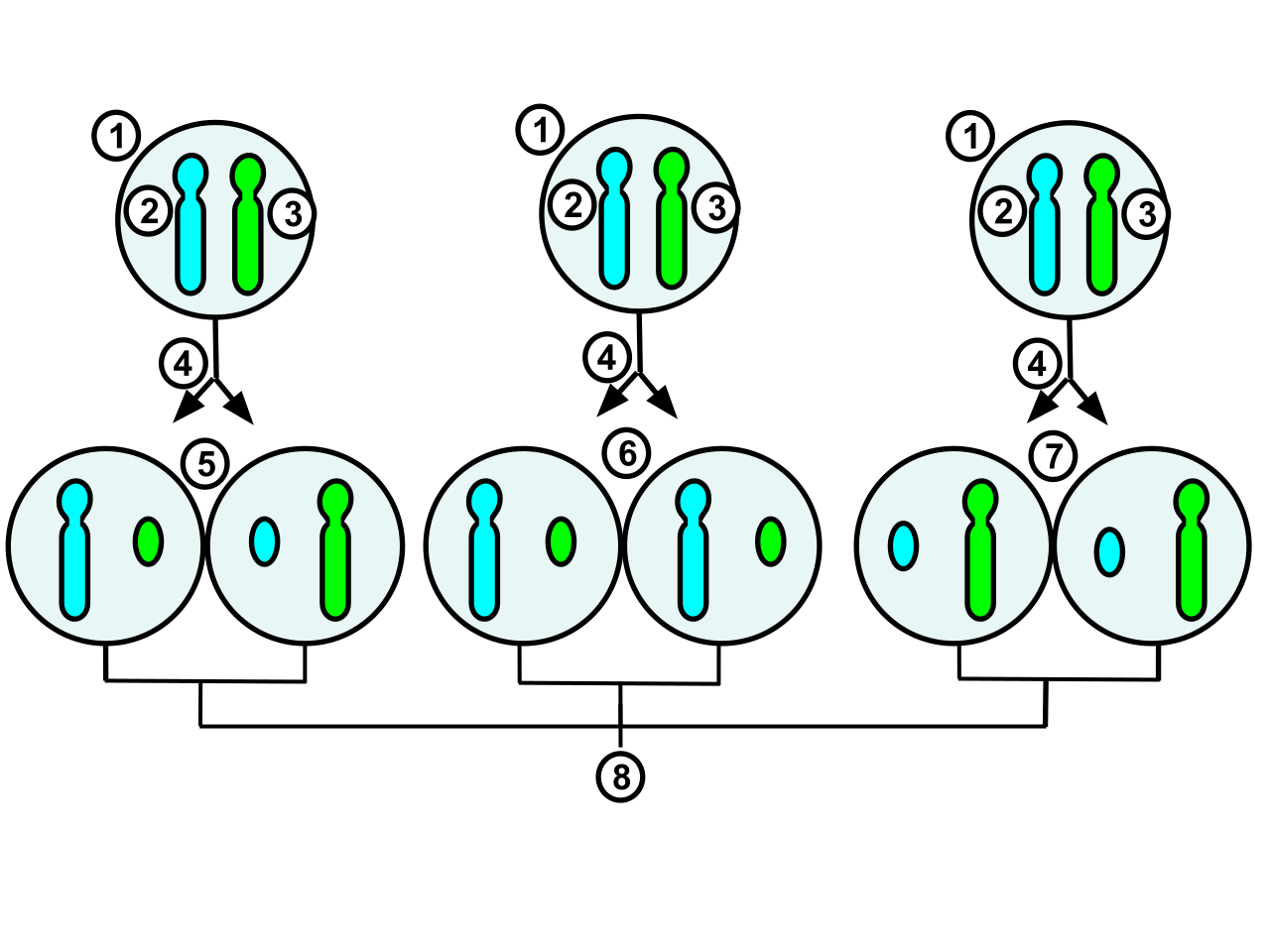
The process and possible outcomes of random X-chromosome inactivation in female human embryonic cells undergoing mitosis. 1.Early stage embryonic cell of a female human 2.Maternal X chromosome 3.Paternal X chromosome 4.Mitosis and random X-chromosome inactivation event 5.Paternal chromosome is randomly inactivated in one daughter cell, maternal chromosome is inactivated in the other 6.Paternal chromosome is randomly inactivated in both daughter cells 7.Maternal chromosome is randomly inactivated in both daughter cells 8.Three possible random combination outcomes.
The process and possible outcomes of random X chromosome inactivation in female human embryonic cells undergoing mitosis. 1.Early stage embryonic cell of a female human 2.Maternal X chromosome 3.Paternal X chromosome 4.Mitosis and random X chromosome inactivation event 5.Paternal chromosome is randomly inactivated in one daughter cell, maternal chromosome is inactivated in the other 6.Paternal chromosome is randomly inactivated in both daughter cells 7.Maternal chromosome is randomly inactivated in both daughter cells 8.Three possible random combination outcomes (Information Source:https://www.khanacademy.org/science/biology/classical-genetics/sex-linkage-non-nuclear-chromosomal-mutations/a/x-inactivation) .
Gliadin (glycoprotein present in wheat) activates zonulin signaling irrespective of the genetic expression of autoimmunity, leading to increased intestinal permeability to macromolecules.
Zonula occludens toxin is being studied as an adjuvant to improve absorption of drugs and vaccines. In 2014 a zonulin receptor antagonist, larazotide acetate (formerly known as AT-1001), completed a phase 2b clinical trial. (W)





_Virus_PHIL_1878_lores.jpg)

{kind=link}